本节主要介绍了单比特与多比特信号跨时钟域(CDC,Clock Domain Crossing)的常见解决办法。
时钟域
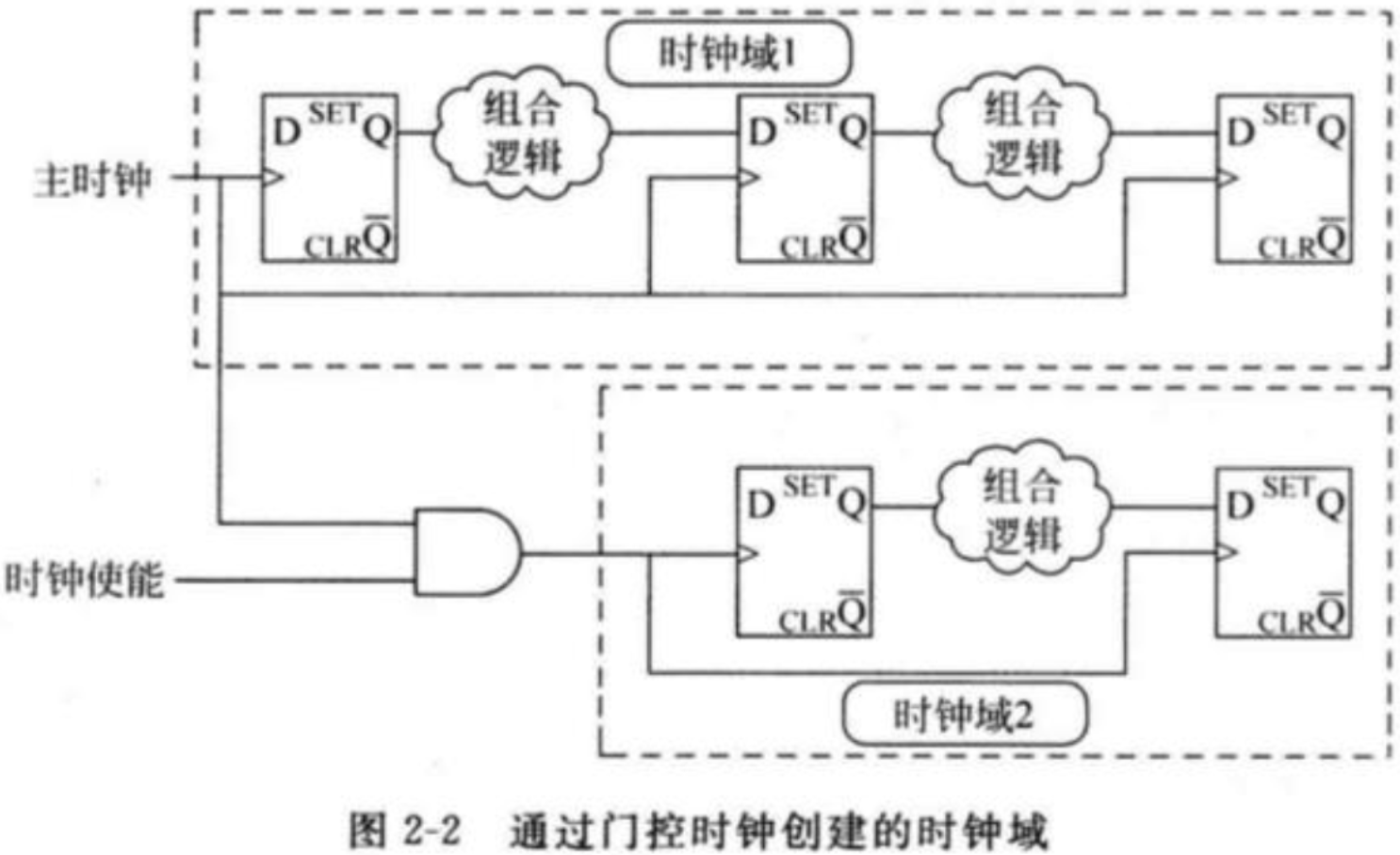
单一时钟域:所谓单一时钟域,是指只有一个独立的网络可以驱动整个设计中所有触发器的时钟端口。
时钟域:是指一组逻辑,这组逻辑中的所有同步单元(触发器、同步RAM块以及流水乘法器等)都使用同一网络作为时钟。
并不一定是FPGA只有一个外部时钟输入就是单时钟域了。例如逻辑门控可以产生时钟,同样PLL也可以产生多个时钟输出供内部逻辑使用,只不过PLL的输出时钟之间一般具有相关性。由于PLL产生了多个时钟输出,所以这样的设计也属于多时钟域设计。
上句话想表达的应该是输入给FPGA内部使用的时钟(由外部时钟分频或者门控等产生),如果是不同的时钟,那么就是多时钟域,如果只有一个时钟,那么就是单时钟域。
单比特信号跨时钟域的同步处理
- 跨时钟域是指设计中存在两个或两个以上异步时钟域。(我目前对异步时钟域的理解是,由不同外部时钟源产生的时钟,但好像大家分析问题的时候往往把它当成不同频率或者不同相位的时钟了)
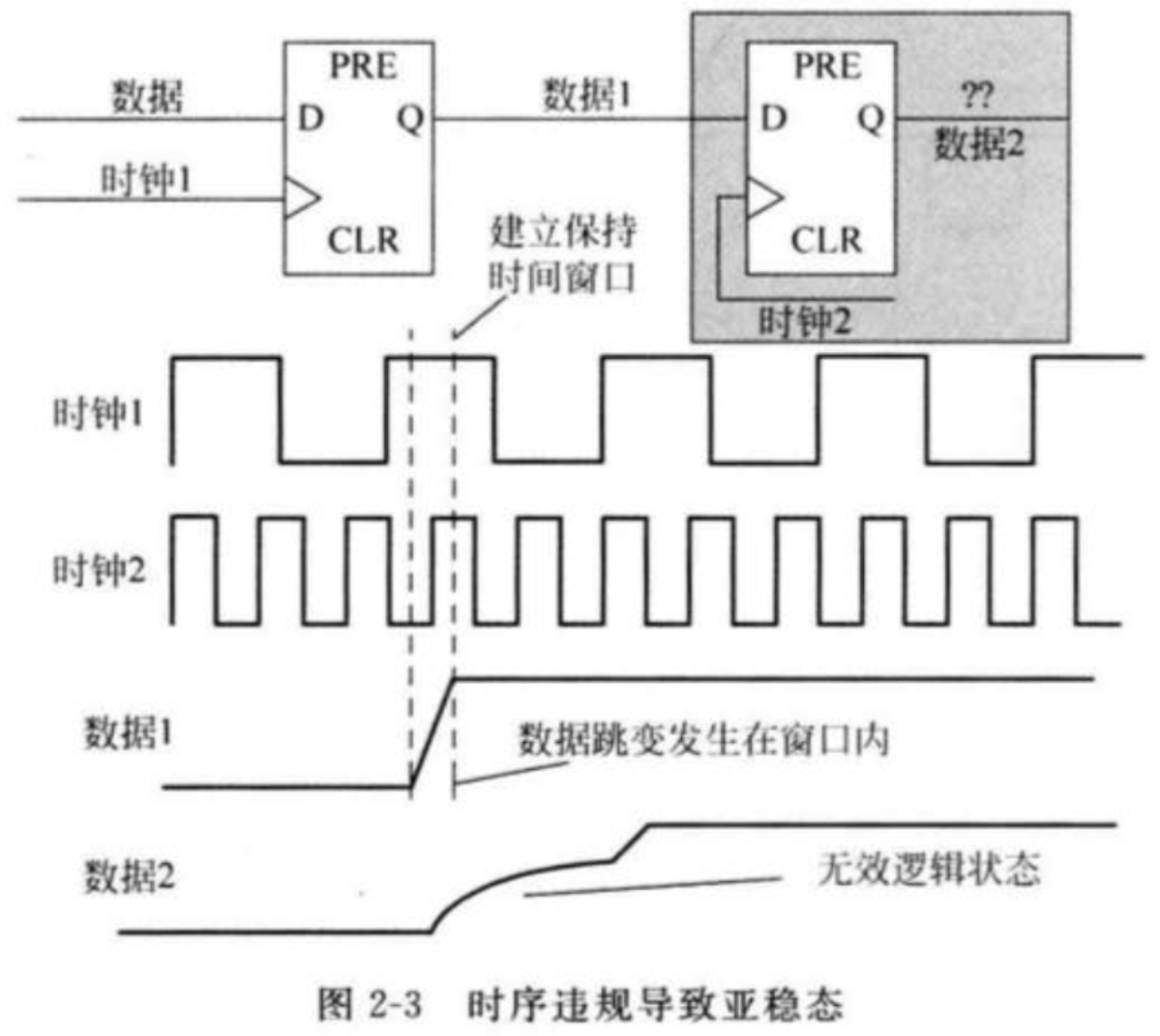
1.亚稳态及其危害
对于沿触发的触发器来说,其输出存在“1”或“0”两个有效状态。
触发器的建立时间和保持时间在时钟上升沿左右定义了一个时间窗口,如果触发器数据输入端口上的数据在这个时间窗口内发生变化,那么就会产生时序违规。
此时触发器内部的某个节点可能会在一个电压范围内浮动,无法稳定在逻辑0或逻辑1状态。
从时序收敛的角度来说,两个触发器之间的组合逻辑延时要求小于最小的时钟周期,但这种亚稳态信号保持亚稳态的时间,本身就是变相增加了逻辑延时。
2.同步慢速时钟域到快速时钟域
常见的同步器是使用两级寄存器,即使用寄存器打两拍的方式进行同步。所谓的同步器就是采样一个异步信号,采样输出能够同步到到采样时钟的模块。
该方法一般用于同步慢速信号到快速时钟域,因为快时钟域是肯定可以采集到慢时钟域的数据的(如果快速时钟域的时钟频率是慢速时钟域的1.5倍以上,那么同步较慢的控制信号到一个快速时钟域通常来说不会有问题),所以需要解决的就是亚稳态的问题
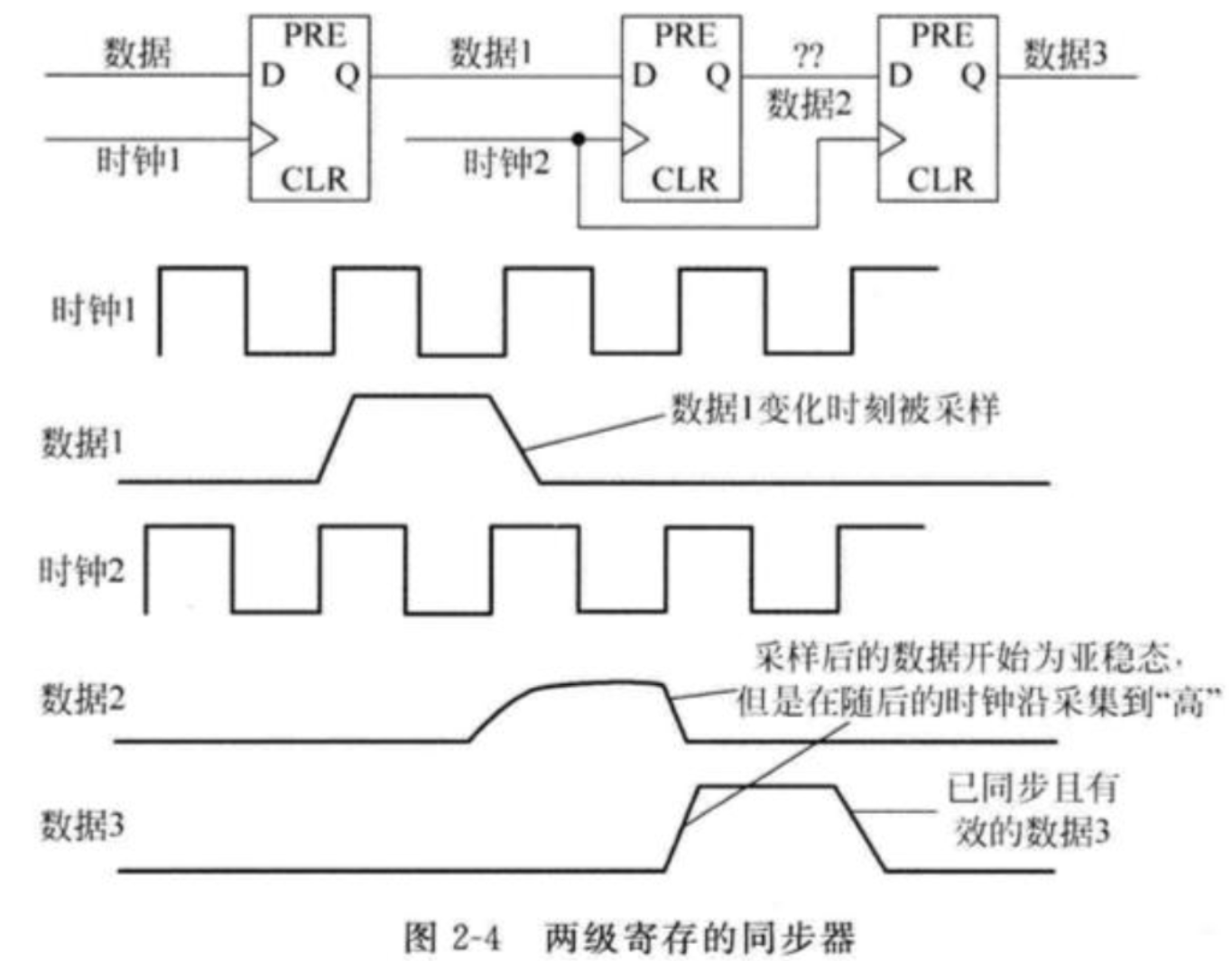
当然,仍然有可能级联的第二个寄存器输出还会表现为非稳定状态,但是这种双寄存同步器已经可以解决大部分亚稳态问题。在设计这种同步器的时候应当注意遵循以下原则:
级联的寄存器必须使用同一个采样时钟
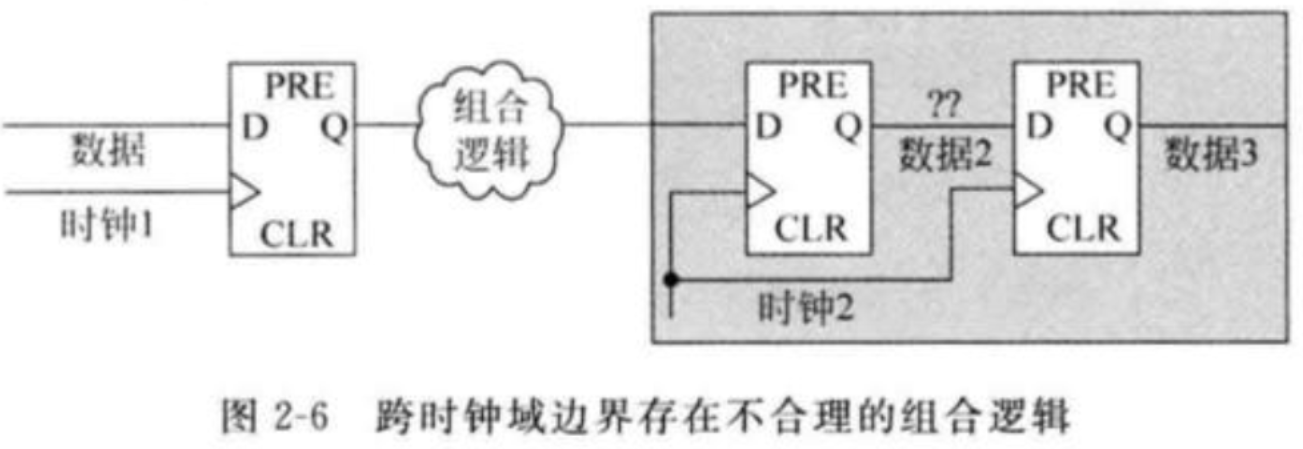
发送端时钟域寄存器输出和接收端异步时钟域级联寄存器输入之间不能有任何其他组合逻辑。因为由于组合逻辑会产生毛刺,这样同步器很有可能采样到不需要的数据。
同步器中级联的寄存器除了最后一个寄存器外所有的寄存器只能有一个扇出,即其只能驱动下一级寄存器的输入
另外,只要同步器中寄存器链处于同一时钟域,那么寄存器链中寄存器路径之间是可以存在组合逻辑的。
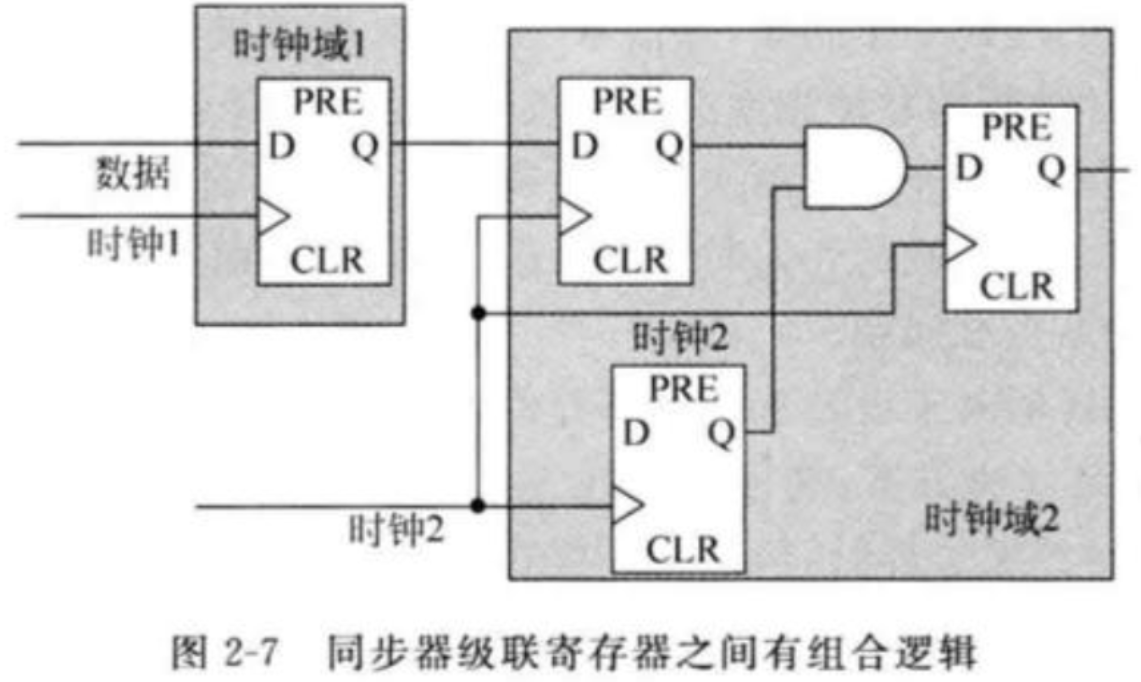
一些高速设计中需要再额外加入一级寄存器来增加MTBF(平均故障间隔时间),也即同步器中两级寄存器的MTBF太短。
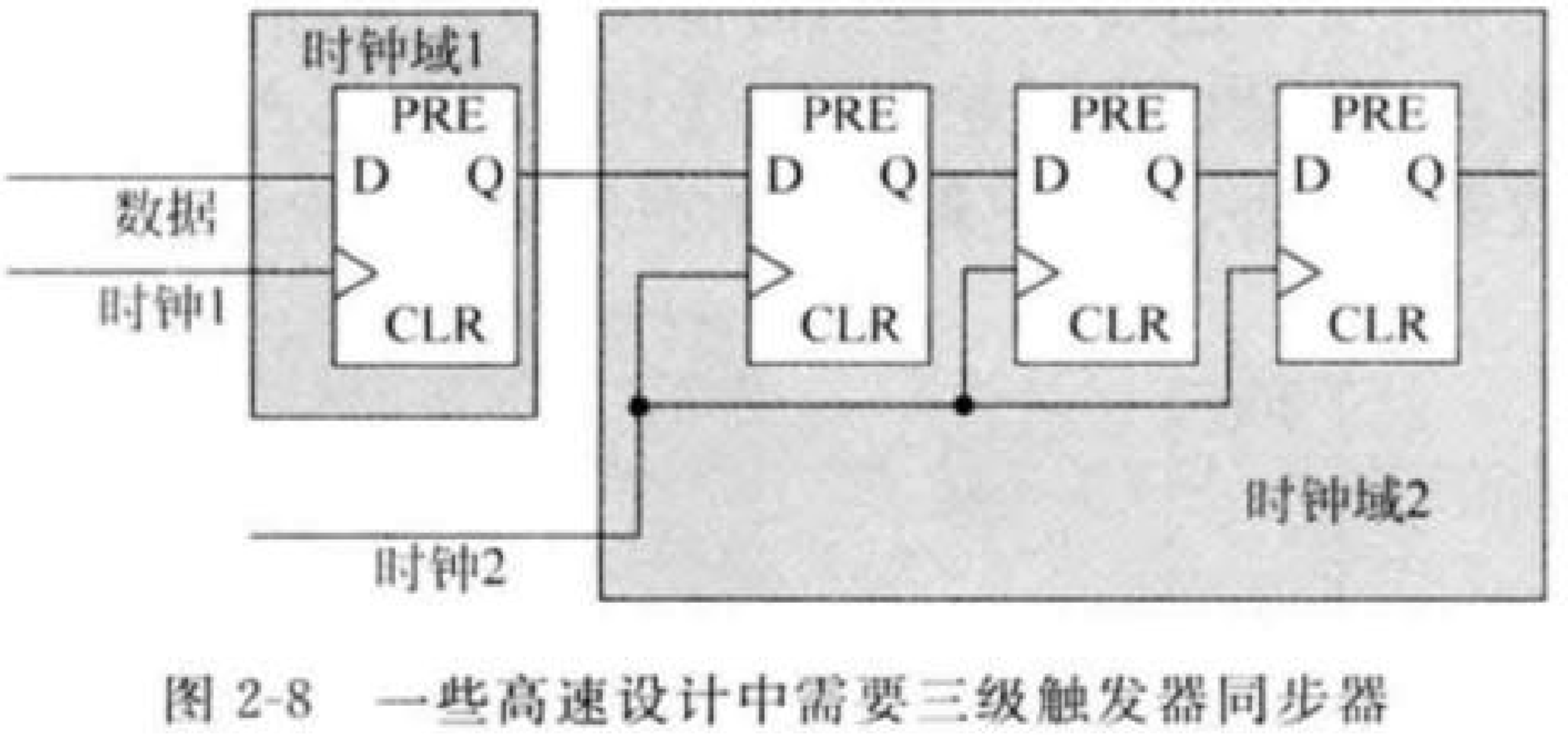
3.同步快速信号到慢速时钟域
如果丢失信号采样值对于设计来说是不允许的,那么有两种通用的应用方法可以解决这个问题:
- 一个是开环解决方案,确保信号在无须确认的情况下可以被采集
- 另一个是闭环解决方案,即在跨时钟域边界时,信号需要接收端的反馈确认。
开环解决方案是:仍然采取之前介绍的打两拍同步器来采样跨时钟域信号,但是前提是需要先将目标展宽,最佳的脉宽是至少为采样时钟周期的1.5倍,这样跨时钟域信号将会被接收时钟域的时钟至少稳定地采样一次。
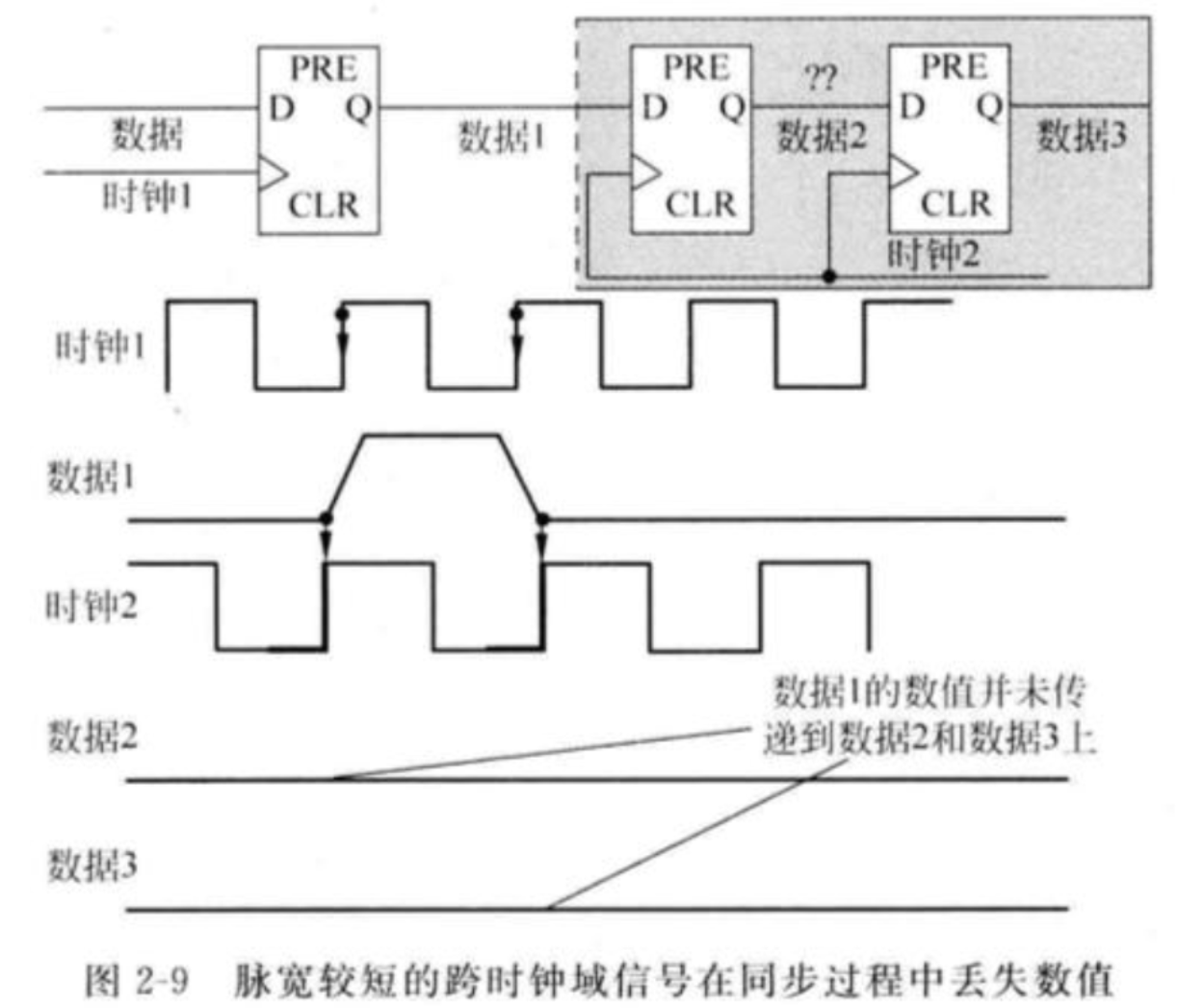
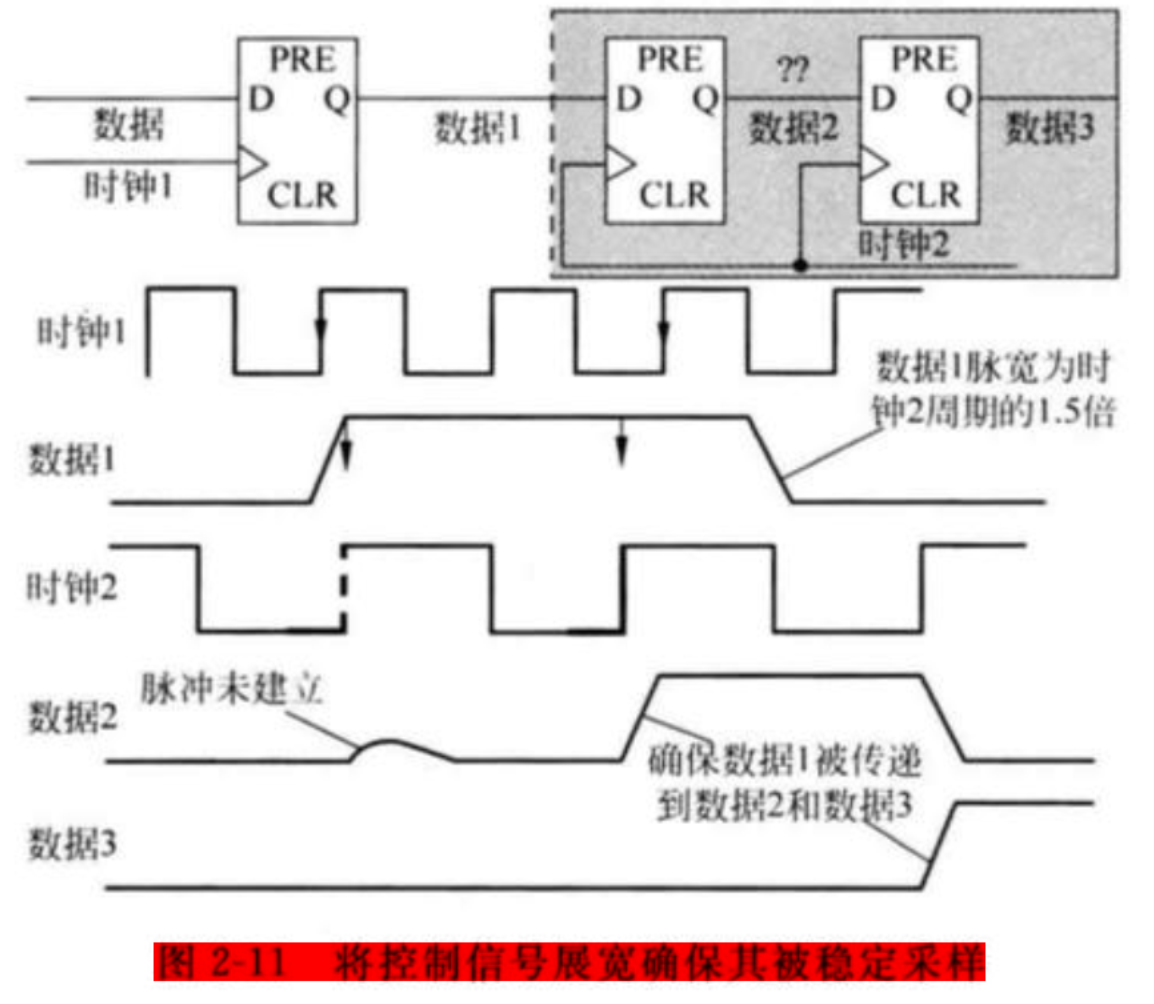
其中脉宽拓展可以采用:高电平用或门拓展,低电平用与门拓展
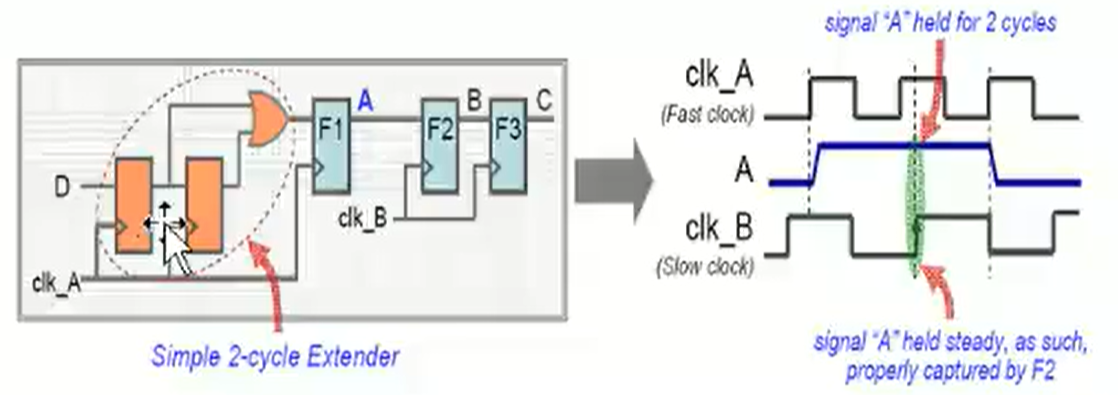
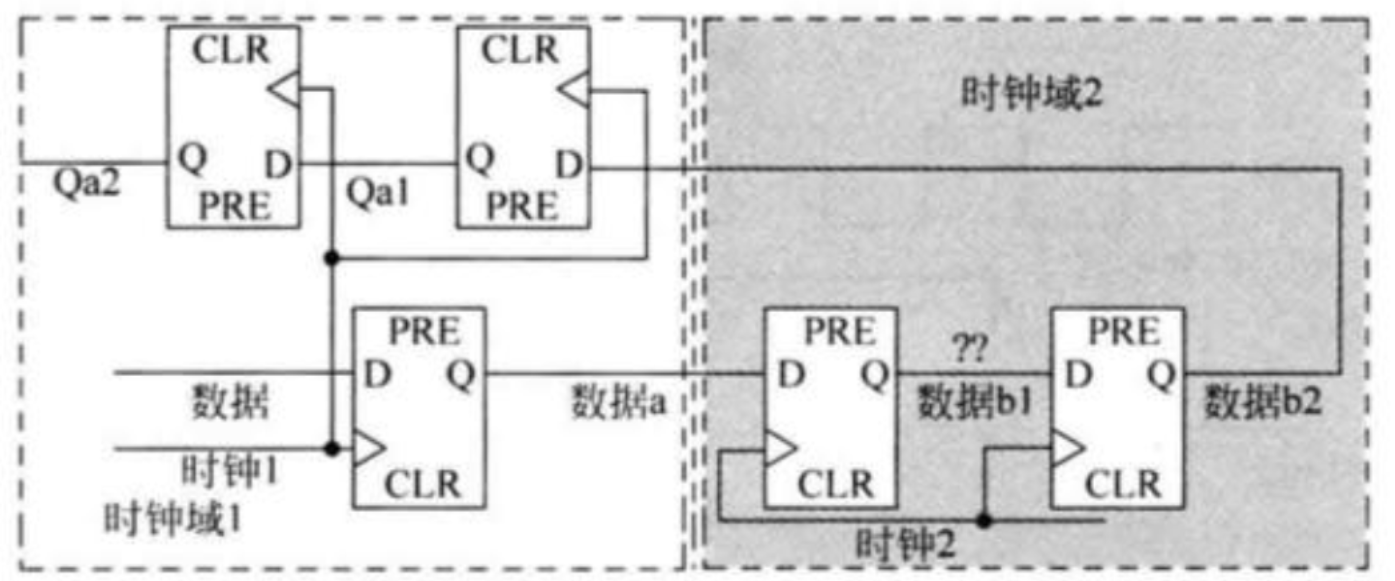
闭环解决方案是:在发送时钟域将数据同步到接收时钟域,再通过反馈回发送时钟域,通过一定逻辑判断,只有当接收数据与发送数据相等时,才传输第下一个数据
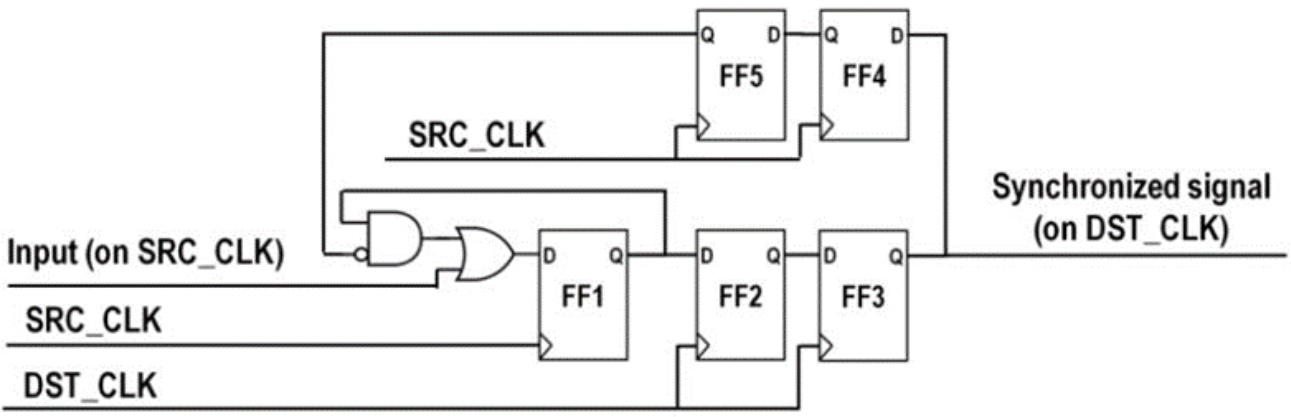
- FF1由源时钟驱动,输入变高,FF1输出变高。FF1的Q输出反馈通过与门和或门保证了在FF5输出为0时,只要FF1输出变高,FF1输出就一直保持高。直到FF3同步输出变成1后,FF5输出变成1,与门输出0。这时只要输入为0,FF1输出即为0。
多比特信号跨时钟域同步处理
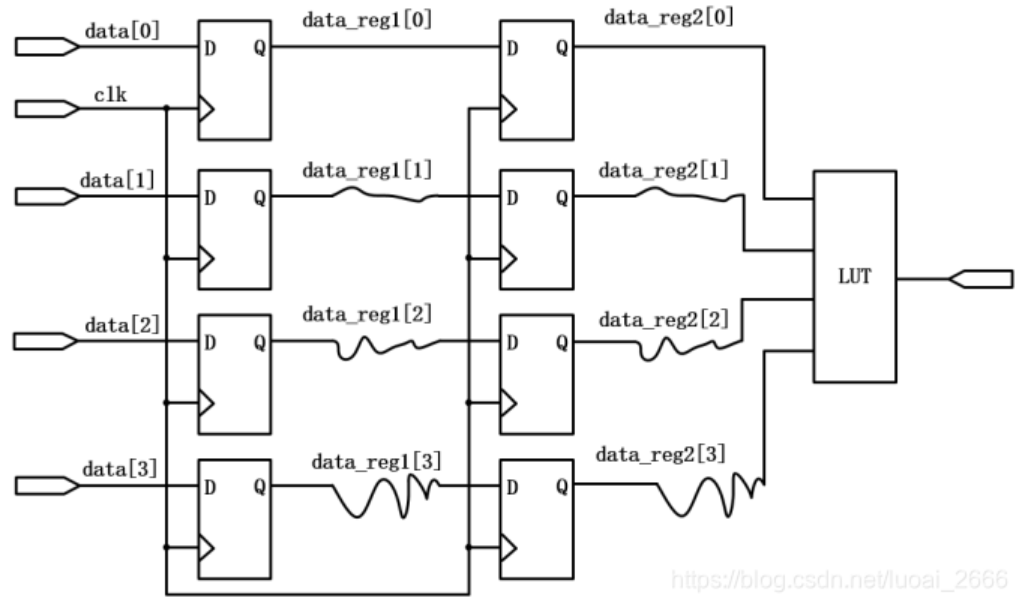
为什么多比特数据跨时钟域时不能采用打两拍的方式处理?如下图所示,每个寄存器的位置不同,布局布线和逻辑的不同会导致每比特数据到达下一级寄存器的延时不同,而且延时会随着打拍数的增加、数据位宽的增加、时钟频率的增大而变得更加恶劣
多比特信号跨时钟域同步处理通常采用以下四种方式:
- 多比特信号融合策略:即在可能的情况下,将多比特跨时钟信号融合成单比特跨时钟域信号
- MUX同步器:它适用的场景理论上也得是让目的时钟域能检测到数据,也就是说要么数据持续时间够长(从快时钟域到慢时钟域),要么是从数据本身在较慢的时钟域内。
- 多周期路径规划策略:即使用同步加载信号来安全地传递多比特跨时钟域信号
- 使用格雷码传递多比特跨时钟域信号
1.多比特信号融合
将加载和使能两个控制信号融合成一个单比特信号(这两个控制信号本身相同,且同时有效)
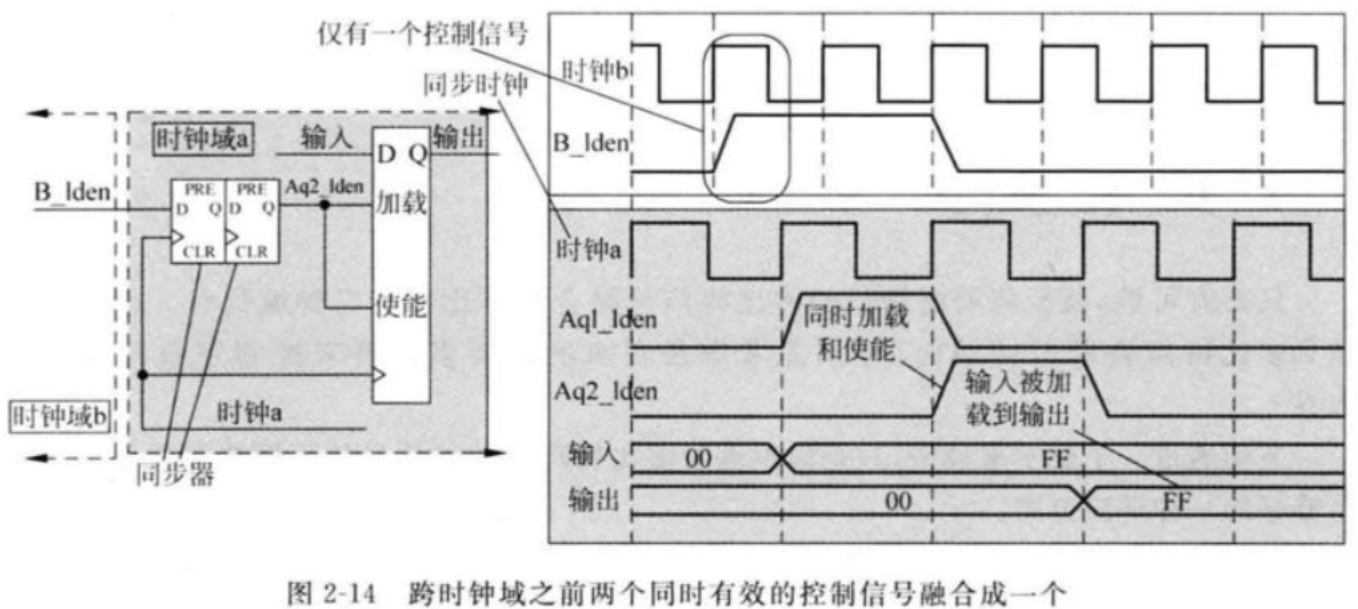
当两个控制信号需要流水间隔一个时钟周期时,要增加一个额外的寄存器将同步后的使能控制信号寄存一拍,这样数据和控制信号形成匹配的流水。
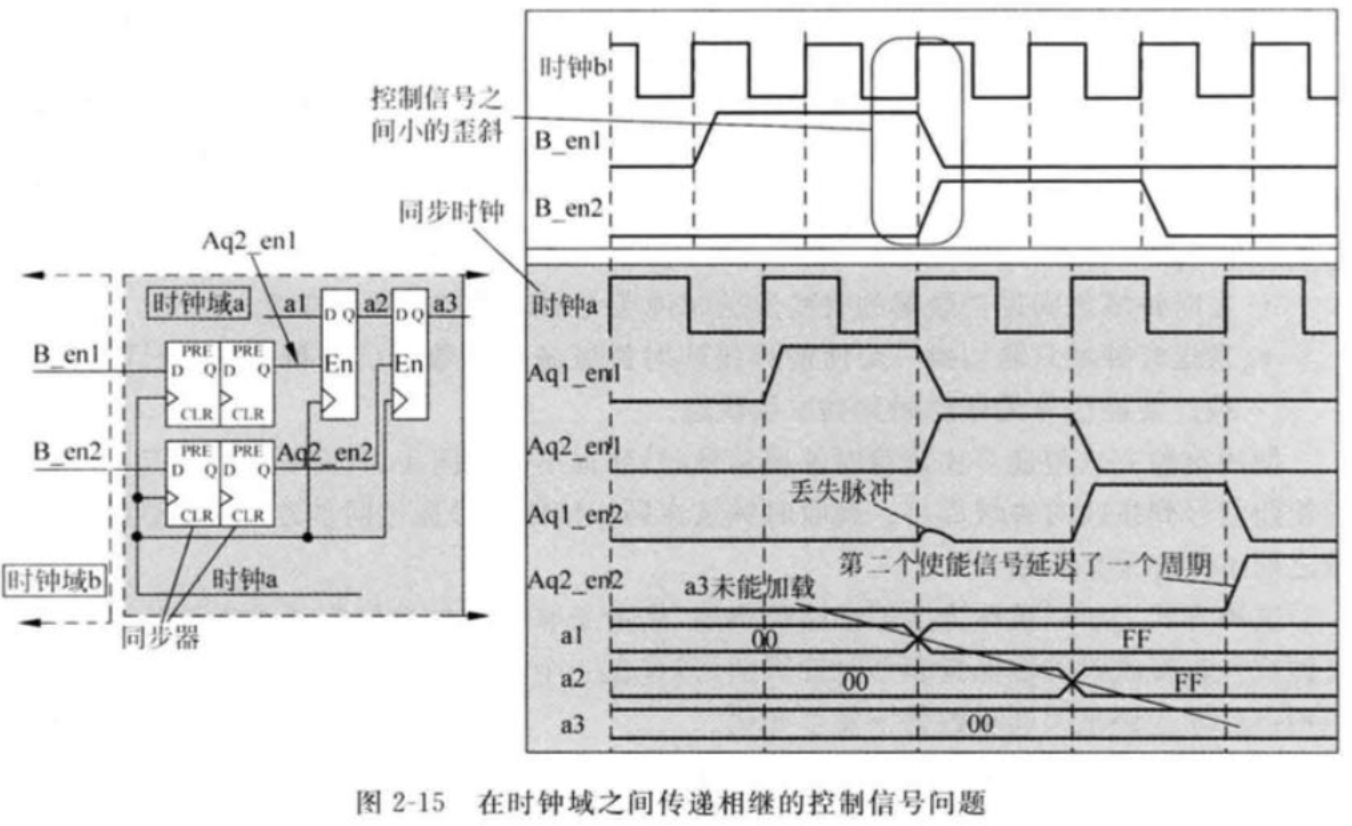
2.MUX同步器

Verilog代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55module mux(
input clk_a ,
input clk_b ,
input arstn ,
input brstn ,
input [3:0] data_in ,
input data_en ,
output reg [3:0] dataout
);
//使能和输入数据在本时钟域下(clk_a)的寄存
reg [3 : 0] data_in_r_a;
reg data_en_r_a;
always @(posedge clk_a or negedge arstn) begin
if(~arstn) begin
data_en_r_a <= 'd0;
end
else begin
data_en_r_a <= data_en;
end
end
always @(posedge clk_a or negedge arstn) begin
if(~arstn) begin
data_in_r_a <= 'd0;
end
else begin
data_in_r_a <= data_in;
end
end
//跨到时钟b下使能信号打两拍
reg [1 : 0] data_en_r_b;
always @(posedge clk_b or negedge brstn) begin
if(~brstn) begin
data_en_r_b <= 'd0;
end
else begin
data_en_r_b <= {data_en_r_b[0], data_en_r_a};
end
end
//在时钟域b下的选择
always @(posedge clk_b or negedge brstn) begin
if(~brstn) begin
dataout <= 'd0;
end
else begin
dataout <= data_en_r_b[1] ? data_in_r_a : dataout;
end
end
endmodule
3.多周期路径规划(MCP)
多周期路径规划指的是,用一个使能信号传输未同步数据到目的时钟域,其中使能信号和数据信号同步输入到目的时钟域,数据信号不需要跨时钟域处理,可以直接给目的时钟域的寄存器,而使能信号在进入目的寄存器之前需要打两拍进行同步。
优点:
- 发射时钟域不需要计算目的时钟域时钟宽度,来进行数据保持;
- 发射时钟域只需要发出一个使能信号,来指示接收时钟域什么时候可以采集数据,这个使能信号可以反馈给发射时钟域,也可以不反馈(如果数据保持时间较长,也就是使能信号间隔比较长)。
重点:
- 数据不需要同步处理而可以直接进行跨时钟域传输,使能信号需要打两拍同步;
- 数据在被采集之前不允许变化;
- 这种方式传输多比特数据非常安全。
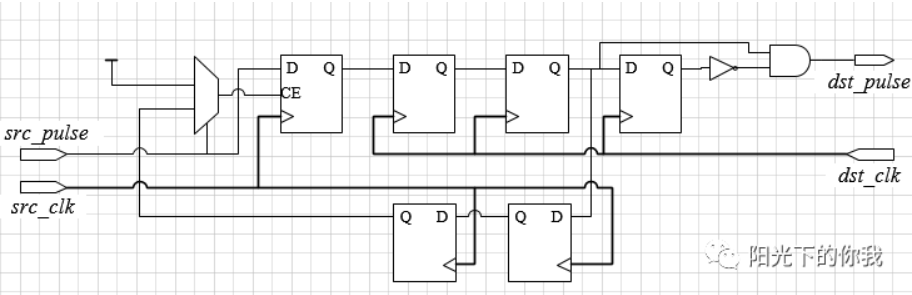
开环方法(脉冲同步电路):总体思路是将A时钟域的脉冲信号转换为电平信号,打两拍后再转换为B时钟域的脉冲信号。(适用于快到慢的脉冲同步,慢到快的脉冲同步可以直接打两拍后再边沿检测)

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44module pulse_detect(
input clk_fast ,
input clk_slow ,
input rst_n ,
input data_in ,
output dataout
);
//在快时钟域下脉冲转电平
reg data_level;
always @(posedge clk_fast or negedge rst_n) begin
if(~rst_n) begin
data_level <= 'd0;
end
else begin
data_level <= data_in ? ~data_level : data_level;
end
end
//跨时钟域,需要打两拍
reg [1 : 0] data_level_2clk;
always @(posedge clk_slow or negedge rst_n) begin
if(~rst_n) begin
data_level_2clk <= 'd0;
end
else begin
data_level_2clk <= {data_level_2clk[0], data_level};
end
end
//在慢时钟域下电平转脉冲(方法即是边沿检测)
reg data_pluse_r;
always @(posedge clk_slow or negedge rst_n) begin
if(~rst_n) begin
data_pluse_r <= 'd0;
end
else begin
data_pluse_r <= data_level_2clk[1];
end
end
assign dataout = data_pluse_r ^ data_level_2clk[1];
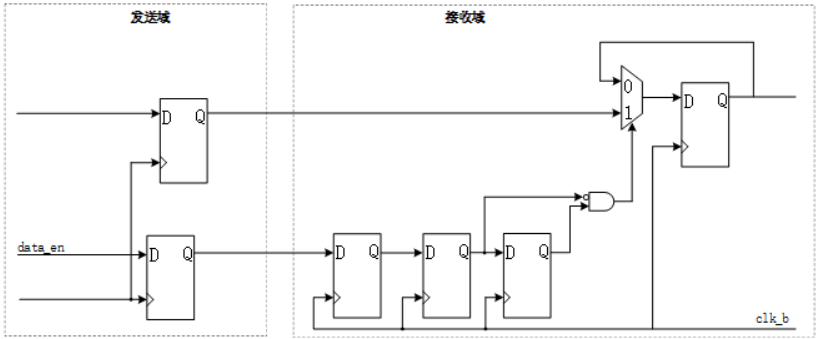
endmodule闭环带反馈(握手)的多周期路径规划:适用于快->慢 or 慢->快 or 不清楚两侧时钟域的快慢
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122module handshake_pulse_sync
(
src_clk , //source clock
src_rst_n , //source clock reset (0: reset)
src_pulse , //source clock pulse in
src_sync_fail , //source clock sync state: 1 clock pulse if sync fail.
dst_clk , //destination clock
dst_rst_n , //destination clock reset (0:reset)
dst_pulse //destination pulse out
);
//PARA DECLARATION
//INPUT DECLARATION
input src_clk ; //source clock
input src_rst_n ; //source clock reset (0: reset)
input src_pulse ; //source clock pulse in
input dst_clk ; //destination clock
input dst_rst_n ; //destination clock reset (0:reset)
//OUTPUT DECLARATION
output src_sync_fail ; //source clock sync state: 1 clock pulse if sync fail.
output dst_pulse ; //destination pulse out
//INTER DECLARATION
wire dst_pulse ;
wire src_sync_idle ;
reg src_sync_fail ;
reg src_sync_req ;
reg src_sync_ack ;
reg ack_state_dly1 ;
reg ack_state_dly2 ;
reg req_state_dly1 ;
reg req_state_dly2 ;
reg dst_req_state ;
reg dst_sync_ack ;
//--========================MODULE SOURCE CODE==========================--
//--=========================================--
// DST Clock :
// 1. generate src_sync_fail;
// 2. generate sync req
// 3. sync dst_sync_ack
//--=========================================--
assign src_sync_idle = ~(src_sync_req | src_sync_ack );
//report an error if src_pulse when sync busy ;
always @(posedge src_clk or negedge src_rst_n)
begin
if(src_rst_n == 1'b0)
src_sync_fail <= 1'b0 ;
else if (src_pulse & (~src_sync_idle))
src_sync_fail <= 1'b1 ;
else
src_sync_fail <= 1'b0 ;
end
//set sync req if src_pulse when sync idle ;
always @(posedge src_clk or negedge src_rst_n)
begin
if(src_rst_n == 1'b0)
src_sync_req <= 1'b0 ;
else if (src_pulse & src_sync_idle)
src_sync_req <= 1'b1 ;
else if (src_sync_ack)
src_sync_req <= 1'b0 ;
end
always @(posedge src_clk or negedge src_rst_n)
begin
if(src_rst_n == 1'b0)
begin
ack_state_dly1 <= 1'b0 ;
ack_state_dly2 <= 1'b0 ;
src_sync_ack <= 1'b0 ;
end
else
begin
ack_state_dly1 <= dst_sync_ack ;
ack_state_dly2 <= ack_state_dly1 ;
src_sync_ack <= ack_state_dly2 ;
end
end
//--=========================================--
// DST Clock :
// 1. sync src sync req
// 2. generate dst pulse
// 3. generate sync ack
//--=========================================--
always @(posedge dst_clk or negedge dst_rst_n)
begin
if(dst_rst_n == 1'b0)
begin
req_state_dly1 <= 1'b0 ;
req_state_dly2 <= 1'b0 ;
dst_req_state <= 1'b0 ;
end
else
begin
req_state_dly1 <= src_sync_req ;
req_state_dly2 <= req_state_dly1 ;
dst_req_state <= req_state_dly2 ;
end
end
//Rising Edge of dst_state generate a dst_pulse;
assign dst_pulse = (~dst_req_state) & req_state_dly2 ;
//set sync ack when src_req = 1 , clear it when src_req = 0 ;
always @(posedge dst_clk or negedge dst_rst_n)
begin
if(dst_rst_n == 1'b0)
dst_sync_ack <= 1'b0;
else if (req_state_dly2)
dst_sync_ack <= 1'b1;
else
dst_sync_ack <= 1'b0;
end
endmodule关于MCP更详细的解释可见另一篇文章中脉冲同步电路部分:Verilog之进阶级刷题 | ssy的小天地
这里想特意提出来的是:个人觉得MUX同步器其实几乎就是开环的MCP实现方式,毕竟若B时钟域(接收域)的时钟频率是A时钟域(发送域)的时钟频率的几十倍,甚至上百倍。且data_en为脉冲信号时,data_en在快时钟域打完几拍的时间相对于慢时钟域是非常短暂的,此时慢时钟域中的多bit数据信号可能还处于冒险中间态,则此时选通进入快时钟域的数据就是“毛刺”。可以在接收域使用边沿同步器,检测data_en的下降沿,以保证此时的多比特数据一定是稳定的。
3.使用FIFO结构处理多比特跨时钟域信号
- 跨时钟域传输数据用得最多的方法就是使用先入先出结构。FIFO可以用于在两个异步时钟域之间传输多比特信号。格雷码常用于在异步时钟域之间传递多比特计数值,且多用于FIFO内。
- 有关FIFO的详细内容具体见我的另一篇文章:FPGA数字信号处理之FIFO | ssy的小天地 (ssy1938010014.github.io)
