本节主要对常见的编解码方式进行学习与记录。
格雷编码与解码
格雷码的主要特点是相邻编码值中只有一个比特发生变化
格雷编码被广泛应用于使用两个不同时钟的异步FIFO中。
当位宽为多个比特的信号从一个时钟域传输到另外一个时钟域时,需要如图的转化电路
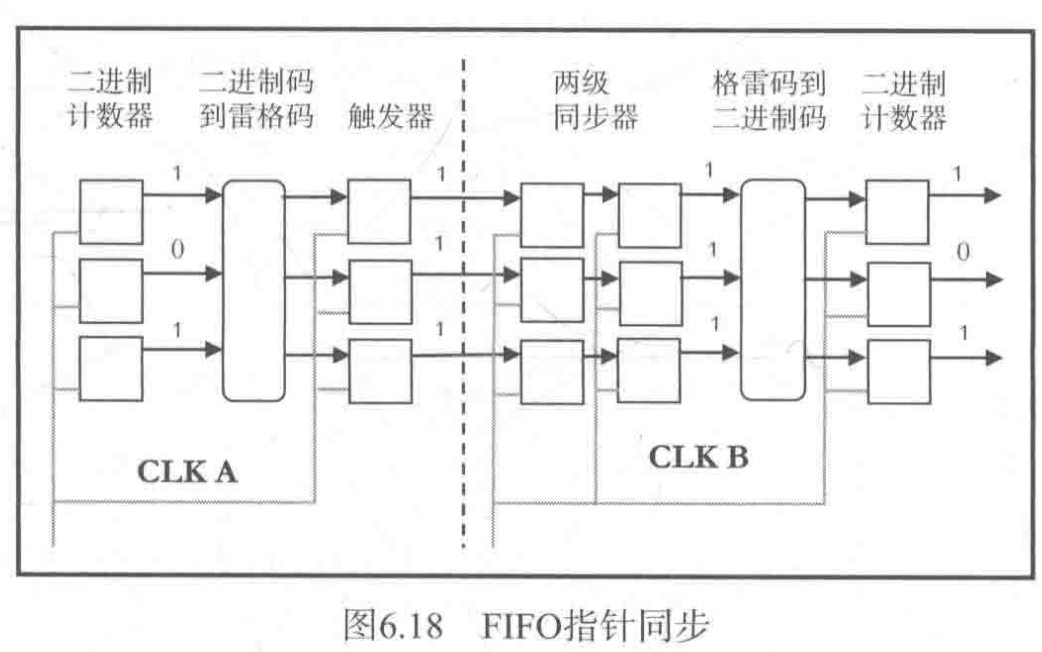
- 该信号开始时转化为格雷码,然后进入源时钟域的寄存器
- 此后,通过两级同步器同步到目的时钟域,实现同步后,通过相反的译码过程,就可以实现多比特值在两个时钟域之间的传递
看了网上很多博客,我觉得只有这篇把在fifo中为什么要使用格雷码说清楚:异步FIFO:为什么要用格雷码_异步fifo为什么用格雷码-CSDN博客
- 其中,有很重要一句话是:在fifo中格雷码的关键不在于发生亚稳态的概率小了,而在于即使发生了亚稳态,也没问题。
- 我的理解是:因为相邻格雷码之间只有1bit发生变化,如果这一bit发生了亚稳态,稳定后,此bit要么是0,要么是1,即在fifo中要么是指针保持不变或者指针加1,但这不会影响fifo的结果,具体看这篇的解释(异步FIFO为什么要使用格雷码(笔记)_异步fifo使用格雷码的目的-CSDN博客)
- 还有一点就是,格雷码计数要变化的bit少,那么可能的中间状态就少。多一个中间状态,就相当于多一次变化,而每次变化都可能出现亚稳态
1.格雷码编码
binary_to_gray.v
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17module binary_to_gray #(
parameter PTR = 8
)(
input [PTR : 0] binary_value,
output [PTR : 0] gray_value
);
genvar i;
generate
for(i = 0; i < PTR; i = i + 1) begin
assign gray_value[i] = binary_value[i] ^ binary_value[i + 1];
end
endgenerate
assign gray_value[PTR] = binary_value[PTR];
endmodule
2.格雷码解码
gray_to_binary.v
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17module gray_to_binary #(
parameter PTR = 8
)(
input [PTR : 0] gray_value,
output [PTR : 0] binary_value
);
assign binary_value[PTR] = gray_value[PTR];
genvar i;
generate
for(i = 0; i < PTR; i = i + 1) begin
assign binary_value[i] = binary_value[i + 1] ^ gray_value[i];
end
endgenerate
endmodule
3.Testbench
transfer_tb.v
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38module transfer_tb;
parameter PTR = 3;
reg clk ;
reg [PTR : 0] binary_value ;
wire [PTR : 0] gray_value ;
wire [PTR : 0] binary_value_tf ;
binary_to_gray #(
.PTR(PTR)
)binary_to_gray_u1(
.binary_value (binary_value),
.gray_value (gray_value )
);
gray_to_binary #(
.PTR(PTR)
)gray_to_binary_u1(
.gray_value (gray_value),
.binary_value (binary_value_tf)
);
initial begin
clk = 1;
end
always #5 clk = ~clk;
integer i;
initial begin
binary_value <= {(PTR + 1){1'b0}};
for(i = 0; i < 10; i = i + 1) begin
@(posedge clk) binary_value <= binary_value + 1;
end
end
endmodule仿真结果:

优先级编码
其实正常想法就是用if-else语句去写,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
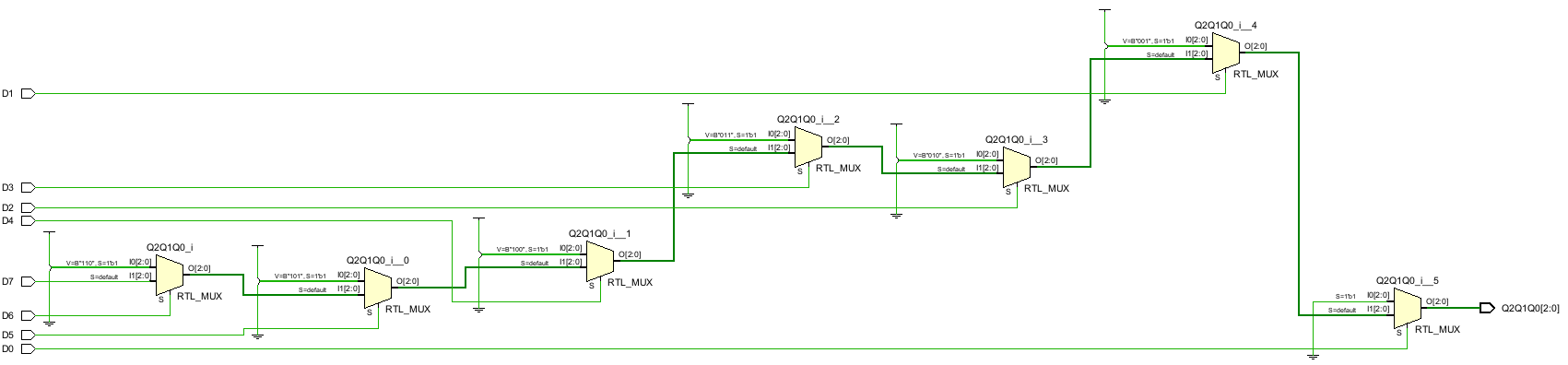
18module priority_encoder(
input D0, D1, D2, D3, D4, D5, D6, D7,
output reg [2 : 0] Q2Q1Q0
);
always @(*) begin
Q2Q1Q0 = 3'b000;
if(D0) Q2Q1Q0 = 3'b000;
else if(D1) Q2Q1Q0 = 3'b001;
else if(D2) Q2Q1Q0 = 3'b010;
else if(D3) Q2Q1Q0 = 3'b011;
else if(D4) Q2Q1Q0 = 3'b100;
else if(D5) Q2Q1Q0 = 3'b101;
else if(D6) Q2Q1Q0 = 3'b110;
else if(D7) Q2Q1Q0 = 3'b111;
end
endmodule其RTL原理图如下:
但在书上看到一种很神奇的case写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20module encoder(
input D0, D1, D2, D3, D4, D5, D6, D7,
output reg [2 : 0] Q2Q1Q0
);
always @(*) begin
Q2Q1Q0 = 3'b000;
case(1'b1)
D0: Q2Q1Q0 = 3'b000;
D1: Q2Q1Q0 = 3'b001;
D2: Q2Q1Q0 = 3'b010;
D3: Q2Q1Q0 = 3'b011;
D4: Q2Q1Q0 = 3'b100;
D5: Q2Q1Q0 = 3'b101;
D6: Q2Q1Q0 = 3'b110;
D7: Q2Q1Q0 = 3'b111;
endcase
end
endmodule其RTL原理图如下:
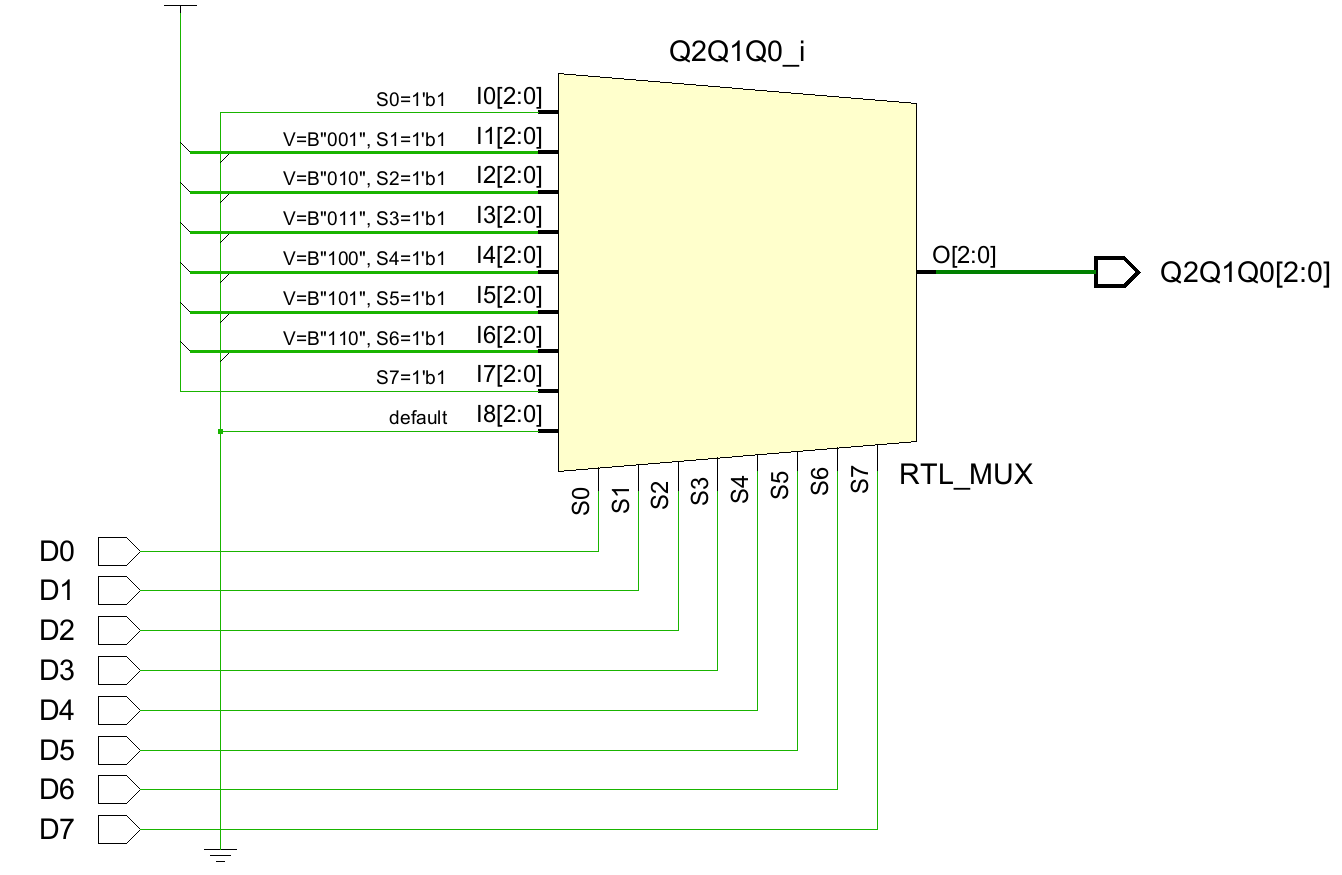
其实它相当于是对D0~D7依次扫描,优先级依次减小,哪个等于1,就执行其后对应的语句
其实这两种写法综合出来的资源是一样的,都如下图所示

