本节主要介绍了Transformer的基本框架,以及相关难以理解的细节
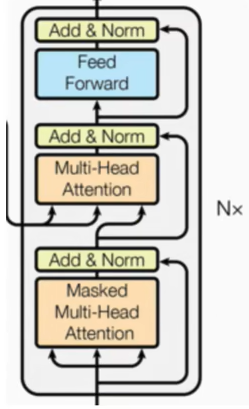
Transformer的基本架构
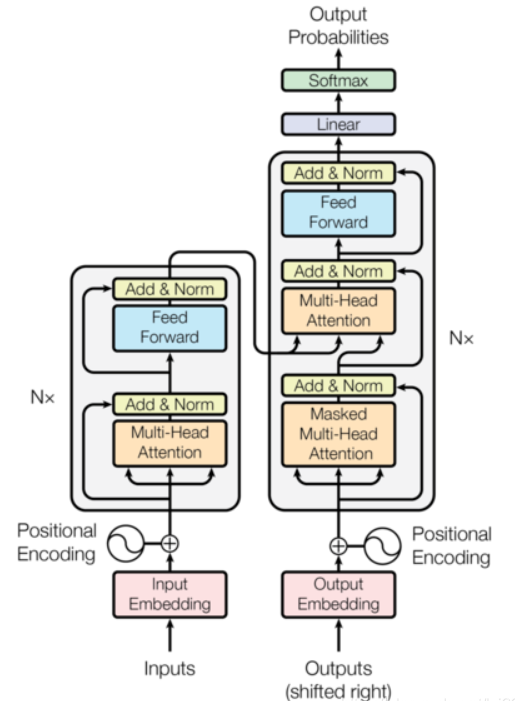
- Transformer总体框架可分为四个部分:
- 输入部分
- 输出部分
- 编码器部分
- 解码器部分
1.输入部分
源文本嵌入层及其位置编码器
目标文本嵌入层及其位置编码器
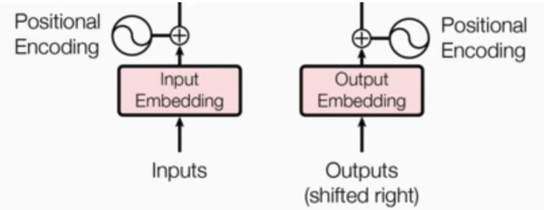
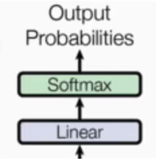
2.输出部分
线性层
softmax层
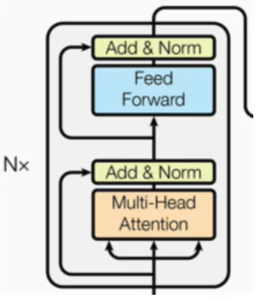
3.编码器部分
由N个编码器堆叠而成
每个编码器层由两个子层连接结构组成
第一个子层连接结构包括一个多头自注意力层和规范化层以及一个残差连接
第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
4.解码器部分
由N个编码器堆叠而成
每个编码器层由三个子层连接结构组成
第一个子层连接结构包括一个多头自注意力层和规范化层以及一个残差连接
第一个子层连接结构包括一个多头注意力层和规范化层以及一个残差连接
第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
位置编码
位置编码器的作用:因为在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在embedding层后加入位置编码器,将词汇位置不同而可能产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失
根据视频中所述公式计算:transformer计算位置编码的过程示例_哔哩哔哩_bilibili
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58import torch
import torch
import numpy
import torch.nn as nn
import torch.nn.functional as F
#关于word embedding,以序列建模为例
#考虑source sentence和target sentence
#构建序列,序列的字符以其在词表中的索引形式表示
batch_size = 2
#单词表的大小
max_num_src_words = 8
max_num_tgt_words = 8
model_dim = 7
#序列的最大长度
max_src_seq_len = 5
max_tgt_seq_len = 5
max_position_len = 5
src_len = torch.tensor([2, 4], dtype = torch.int32)
tgt_len = torch.tensor([4, 3], dtype = torch.int32)
#单词索引构成的句子
src_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(0, max_num_src_words, (L,)), (0, max_src_seq_len - L)), 0)
for L in src_len])
tgt_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(0, max_num_tgt_words, (L,)), (0, max_tgt_seq_len - L)), 0)
for L in src_len])
#构造embedding
src_embedding_table = nn.Embedding(max_num_src_words, model_dim, padding_idx = 7)
tgt_embedding_table = nn.Embedding(max_num_tgt_words, model_dim, padding_idx = 7)
src_embedding = src_embedding_table(src_seq)
tgt_embedding = tgt_embedding_table(tgt_seq)
# print(src_embedding)
# print(tgt_embedding)
#构造position embedding
pos_mat = torch.arange(max_position_len).reshape(-1, 1)
i_mat_even = torch.pow(10000, torch.arange(0, model_dim, 2).reshape(1, -1)/model_dim)
i_mat_odd = torch.pow(10000, torch.arange(1, model_dim, 2).reshape(1, -1)/model_dim)
pe_embedding_table = torch.zeros(max_position_len, model_dim)
pe_embedding_table[:, 0::2] = torch.sin(pos_mat / i_mat_even)
pe_embedding_table[:, 1::2] = torch.cos(pos_mat / i_mat_odd)
pe_embedding = nn.Embedding(max_position_len, model_dim)
pe_embedding.weight = nn.Parameter(pe_embedding_table, requires_grad = False)
src_pos = torch.cat([torch.unsqueeze(torch.arange(max(src_len)), 0) for _ in src_len]).to(torch.int32)
tgt_pos = torch.cat([torch.unsqueeze(torch.arange(max(tgt_len)), 0) for _ in tgt_len]).to(torch.int32)
src_pe_embedding = pe_embedding(src_pos) #只与句子中词的位置有关
tgt_pe_embedding = pe_embedding(tgt_pos)
print(src_pe_embedding)
print(tgt_pe_embedding)结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34tensor([[[0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
1.0000e+00, 0.0000e+00],
[8.4147e-01, 9.6423e-01, 7.1906e-02, 9.9981e-01, 5.1794e-03,
1.0000e+00, 3.7276e-04],
[9.0930e-01, 8.5948e-01, 1.4344e-01, 9.9925e-01, 1.0359e-02,
1.0000e+00, 7.4552e-04],
[1.4112e-01, 6.9325e-01, 2.1423e-01, 9.9832e-01, 1.5538e-02,
9.9999e-01, 1.1183e-03]],
[[0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
1.0000e+00, 0.0000e+00],
[8.4147e-01, 9.6423e-01, 7.1906e-02, 9.9981e-01, 5.1794e-03,
1.0000e+00, 3.7276e-04],
[9.0930e-01, 8.5948e-01, 1.4344e-01, 9.9925e-01, 1.0359e-02,
1.0000e+00, 7.4552e-04],
[1.4112e-01, 6.9325e-01, 2.1423e-01, 9.9832e-01, 1.5538e-02,
9.9999e-01, 1.1183e-03]]])
tensor([[[0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
1.0000e+00, 0.0000e+00],
[8.4147e-01, 9.6423e-01, 7.1906e-02, 9.9981e-01, 5.1794e-03,
1.0000e+00, 3.7276e-04],
[9.0930e-01, 8.5948e-01, 1.4344e-01, 9.9925e-01, 1.0359e-02,
1.0000e+00, 7.4552e-04],
[1.4112e-01, 6.9325e-01, 2.1423e-01, 9.9832e-01, 1.5538e-02,
9.9999e-01, 1.1183e-03]],
[[0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
1.0000e+00, 0.0000e+00],
[8.4147e-01, 9.6423e-01, 7.1906e-02, 9.9981e-01, 5.1794e-03,
1.0000e+00, 3.7276e-04],
[9.0930e-01, 8.5948e-01, 1.4344e-01, 9.9925e-01, 1.0359e-02,
1.0000e+00, 7.4552e-04],
[1.4112e-01, 6.9325e-01, 2.1423e-01, 9.9832e-01, 1.5538e-02,
9.9999e-01, 1.1183e-03]]])
多头自注意机制的结构及其原理
注意力的基本结构:
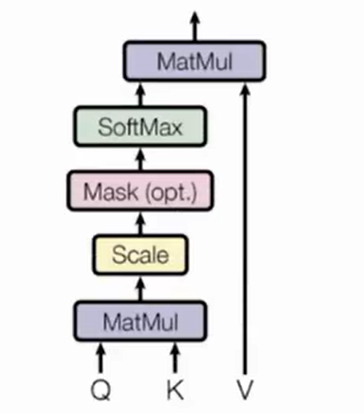
若Q、K来自不同输入,则是注意力机制,若Q、K输入来自同一输入,则是自注意力机制
其计算公式如下:
那么Q、K、V是如何计算得到的呢?
假设以下计算均是针对自注意机制,同一输入分别与三个权重矩阵$W^Q,W^K,W^V$相乘,即可得到Q、K、V
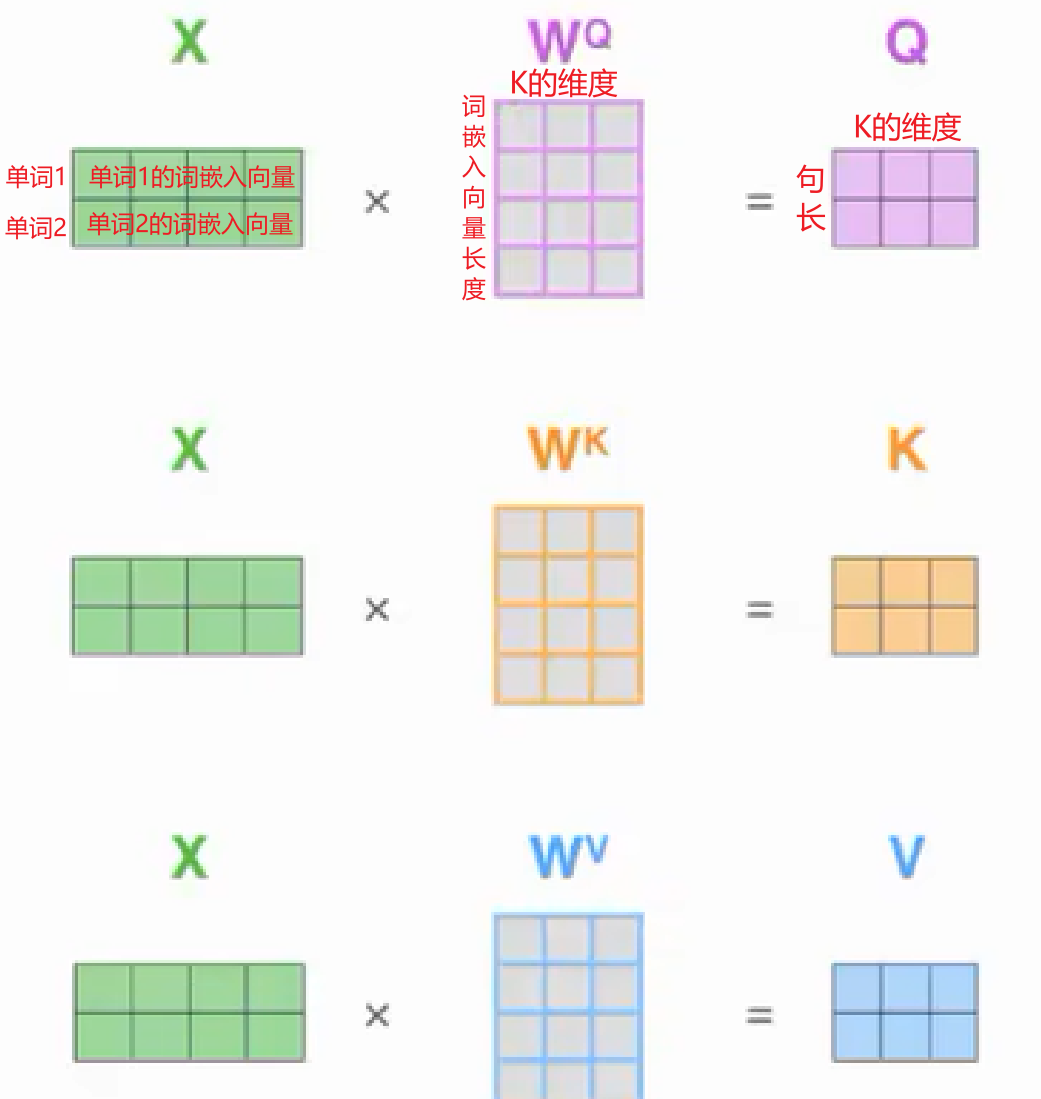
从图中可以很明显的看出来,全连接层能很好的实现这一过程
那么$Q\times K^T$相乘又意味着什么呢?
$softmax(\frac{Q\times K^T}{\sqrt{d_k}})$计算后的结果表示的是Q(约等于输入)中每个单词对K(约等于输入)中每个单词的相关性
不难发现,$Q\times K^T$后的维度变成了$(len\times len)$
所以我的理解是,首先通过全连接层将词向量维度变成K的维度,接着通过attention操作变到句长的维度,以便获取单词对单词之间相关性的权重矩阵
最后,用这个权重矩阵对V进行加权求和,而这个V可以理解为一个初始答案,经过权重矩阵的训练之后,得到一个尽可能标准的答案,最终Z的最后两个维度为$(len\times d_v)$
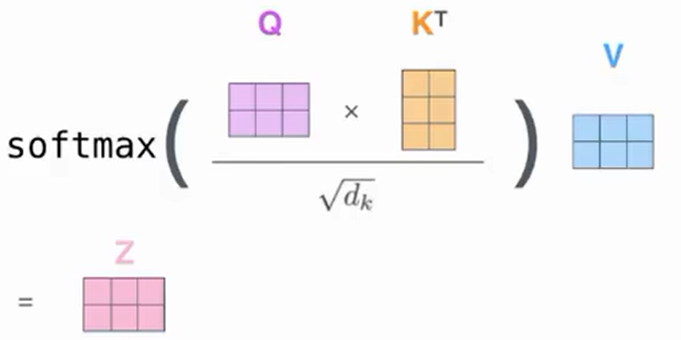
那么什么是多头注意力机制呢?
- 就是用不同的矩阵与输入相乘,从而得到不同组的Q、K、V,以此获得更多空间维度的特征
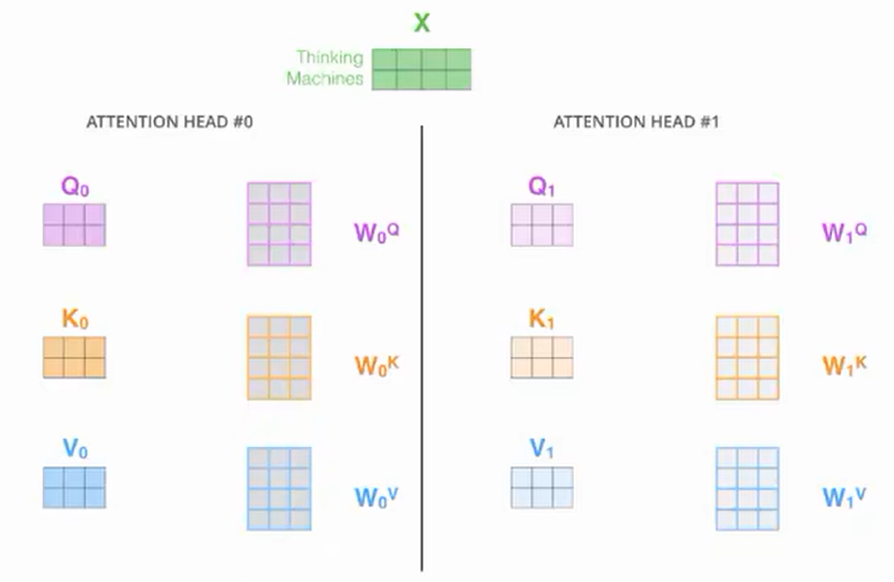
其实现代码如下,值得细细品味:
- 首先在
self.W_Q的nn.Linear中,本来是将d_model维变到d_k维,但是由于是多头,故乘以了一个n_heads - 其次在
self.linear的nn.Linear中,需要将维度变回d_model,以便下一次堆叠计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
## 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;
##输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
##下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致额,所以一看这里都是dk
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
##然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下
## 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]- 首先在
两个输入与标签值的理解
- 在训练时一个输入是input,另一个输入是掩码遮掩的标签值,经过网络训练后的结果与标签值比较,计算损失,以不断调整网络,详情见这篇文章:举个例子讲下transformer的输入输出细节及其他 - 知乎 (zhihu.com)
- 而在测试时,另一个输入需要选输入\
起始符,将网络得到的结果再输入,以此迭代,详情见这篇文章:Transformer的PyTorch实现 - mathor (wmathor.com)中的测试部分
BatchNorm与LayerNorm的区别
- BN是针对不同batch下同一特征求均值和方差
- LN是针对一个样本中所有单词求均值和方差
- 可以看下面两个视频帮助理解
Transformer的示例代码
1 | ## from https://github.com/graykode/nlp-tutorial/tree/master/5-1.Transformer |
Reference
- 这是B站目前讲的最好的【Transformer实战】教程!带你从零详细解读Transformer模型 一次学到饱!——人工智能、深度学习、神经网络_哔哩哔哩_bilibili(只适合学习基本架构部分)
- 19、Transformer模型Encoder原理精讲及其PyTorch逐行实现_哔哩哔哩_bilibili(位置编码以及mask的细节可以看这个视频)
- 【深度学习】Transformer中的mask机制超详细讲解_Articoder的博客-CSDN博客(mask的理解还可参考这篇文章)
- pytorch 中矩阵乘法总结 - 知乎 (zhihu.com)
- Pytorch - masked_fill方法参数详解与使用_HW140701的博客-CSDN博客
- PyTorch碎片:F.pad的图文透彻理解_pytorch f.pad_柚有所思的博客-CSDN博客
- Transformer 原理详解_哔哩哔哩_bilibili(将transformer的原理细节可视化展示出来了,入门推荐)
- 2.Decoder代码解读_哔哩哔哩_bilibili(看完上一个视频的原理详解后,可以看这个视频结合代码进一步理解模型)
- Transformer的PyTorch实现_哔哩哔哩_bilibili
- Pytorch中nn.ModuleList和nn.Sequential的用法和区别_modulelist是什么作用_叫我西瓜超人的博客-CSDN博客
