本节主要介绍了文本情感分析的基本概念以及相关代码示例
情感分析基本概念
情感分析:计算机帮助用户快速获取、整理和分析相关评价信息,对带有情感色彩的主观性文本进行分析、处理、归纳和推理
情感分析包括情感分类、观点抽取、观点问答、观点摘要
情感分类:指根据文本所表达的含义和情感信息将文本划分为褒扬的或贬义的两种或几种类型,是对文本作者倾向性和观点、态度的划分,也称为倾向性分析
情感分类的流程:
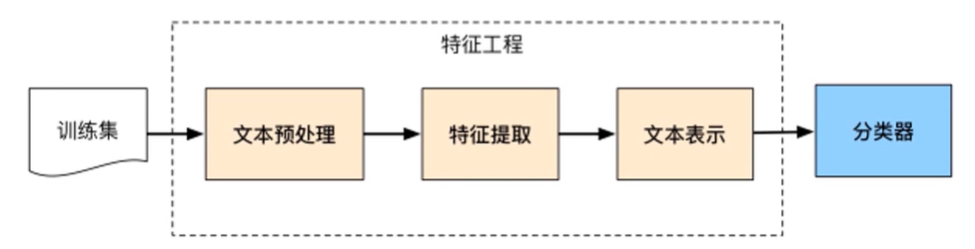
数据集下载与处理
stopwords(句子中没啥含义的词,如的、那么等等)下载地址:stopwords/hit_stopwords.txt at master · goto456/stopwords (github.com)
对原始数据进行相关处理,就可以得到相关字典,并且可以得到分词后的结果:data_processing.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import jieba
data_path = "sources/weibo_senti_100k.csv"
data_list = open(data_path, 'r', encoding='utf-8').readlines()[1:]
data_stop_path = "sources/hit_stopwords.txt"
stops_word = open(data_stop_path, 'r', encoding='utf-8').readlines()
stops_word = [line.strip() for line in stops_word] #过滤掉字符串两端的空格与换行符
stops_word.append(' ')
stops_word.append('\n') #再添加空格与换行符
voc_dict = {}
min_seq = 1
top_n = 1000 #字典的最大长度
UNK = "<UNK>"
PAD = "<PAD>"
for item in data_list:
label = item[0]
content = item[2:].strip() #利用.strip()移除结尾的换行符
seg_list = jieba.cut(content, cut_all = False) #利用jieba得到一个精确的分词结果
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
if seg_item in voc_dict.keys():
voc_dict[seg_item] = voc_dict[seg_item] + 1
else:
voc_dict[seg_item] = 1
voc_list = sorted([_ for _ in voc_dict.items() if _[1] > min_seq],
key = lambda x:x[1],
reverse = True)[:top_n]
voc_dict = {word_count[0]: idx for idx, word_count in enumerate(voc_list)}
voc_dict.update({UNK: len(voc_dict), PAD: len(voc_dict) + 1})
ff = open("sources/dict.txt", 'w')
for item in voc_dict.keys():
ff.writelines("{},{}\n".format(item, voc_dict[item]))
ff.close()得到的字典如下:

处理原始数据生成数据集,将每个句子用一个数字向量表示:
- 返回列表中第一个元素为标签(有batch_size个),
- 第二个元素为处理后的输入数据(即每个句子由一个序列表示,序列中的每个元素为一个数字,这个数字为词在字典词表中的位置)
1
2
3
4
5
6
7[tensor([0, 0, 1, 1, 0, 0, 1, 1, 0, 0]), tensor([[ 12, 453, 1000, ..., 1001, 1001, 1001],
[ 8, 1000, 37, ..., 1001, 1001, 1001],
[1000, 1000, 1000, ..., 1001, 1001, 1001],
...,
[ 8, 1000, 1000, ..., 1001, 1001, 1001],
[1000, 1000, 1000, ..., 1001, 1001, 1001],
[ 162, 1000, 243, ..., 1001, 1001, 1001]], dtype=torch.int32)]
datasets.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82from torch.utils.data import Dataset, DataLoader
import jieba
import numpy as np
def load_data(data_path, data_stop_path):
data_list = open(data_path, 'r', encoding='utf-8').readlines()[1:]
stops_word = open(data_stop_path, 'r', encoding='utf-8').readlines()
stops_word = [line.strip() for line in stops_word] #过滤掉字符串两端的空格与换行符
stops_word.append(' ')
stops_word.append('\n') #再添加空格与换行符
data = []
max_len_seq = 0
for item in data_list:
label = item[0]
content = item[2:].strip() #利用.strip()移除结尾的换行符
seg_list = jieba.cut(content, cut_all = False) #利用jieba得到一个精确的分词结果
seg_res = []
for seg_item in seg_list:
if seg_item in stops_word:
continue
seg_res.append(seg_item)
if len(seg_res) > max_len_seq:
max_len_seq = len(seg_res) #获取最长句子的长度
data.append([label, seg_res])
return data, max_len_seq
def read_dict(voc_dict_path): #用于读取字典数据
voc_dict = {}
dict_list = open(voc_dict_path).readlines()
for item in dict_list:
item = item.split(',')
voc_dict[item[0]] = int(item[1].strip()) #将字符串转为整形
return voc_dict
class text_ClS(Dataset):
def __init__(self, voc_dict_path, data_path, data_stop_path):
super(text_ClS, self).__init__()
self.voc_dict = read_dict(voc_dict_path) #加载字典
#加载分词后的数据(包括标签和句子)以及句子中所含单词数的最大值
self.data_path = data_path
self.data_stop_path = data_stop_path
self.data, self.max_len_seq = load_data(self.data_path, self.data_stop_path)
np.random.shuffle(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, index):
data = self.data[index]
label = int(data[0]) #每一个index对应的标签
word_list = data[1] #和句子
input_idx = []
for word in word_list: #获取每个词在字典中对应的编号
if word in self.voc_dict.keys():
input_idx.append(self.voc_dict[word])
else:
input_idx.append(self.voc_dict["<UNK>"])
if len(input_idx) < self.max_len_seq:
input_idx += [self.voc_dict["<PAD>"] for _ in range(self.max_len_seq -len(input_idx))]
data_vector = np.array(input_idx) #此时每个句子由一个序列表示,序列中的每个元素为一个数字
return label, data_vector
def data_loader(dataset, config):
return DataLoader(dataset, batch_size = config.batch_size, shuffle = config.is_shuffle)
# if __name__ == "__main__":
# data_path = "sources/weibo_senti_100k.csv"
# data_stop_path = "sources/hit_stopwords.txt"
# dict_path = "sources/dict.txt"
# train_dataloader = data_loader(data_path, data_stop_path, dict_path)
# # for i, batch in enumerate(train_dataloader):
# # print(batch)
网络搭建
词嵌入:将句子中单词在字典中的索引,用与之对应的词向量表示
nn.LSTM相关参数解释:pytorch中LSTM参数详解(一张图帮你更好的理解每一个参数)_pytorch lstm参数_xjtuwfj的博客-CSDN博客
models.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from configs import Config
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embeding = nn.Embedding(config.n_vocab,
config.embed_size,
padding_idx = config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed_size,
config.hidden_size,
config.num_layers,
bidirectional = True,
batch_first = True,
dropout = config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed_size, config.num_classes)
#由于LSTM层设置为双向的,因此每个时间步的输出包括正向和反向的隐藏状态,故需要*2
self.softmax = nn.Softmax(dim = 1)
def forward(self, x):
embed = self.embeding(x) #[batchsize, seqlen, embed_size]
out, _ = self.lstm(embed)
out = torch.cat((embed, out), dim = 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).reshape(out.size()[0], -1)
out = self.fc(out)
out = self.softmax(out)
return out
# if __name__ == "__main__":
# cfg = Config()
# model_textcls = Model(config = cfg)相关配置数据文件configs.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import torch
class Config():
def __init__(self):
self.n_vocab = 1002
self.embed_size = 256
self.hidden_size = 256
self.num_layers = 3
self.dropout = 0.8
self.num_classes = 2
self.pad_size = 32
self.batch_size = 128
self.is_shuffle = True
self.learn_rate = 0.001
self.num_epochs = 100
self.devices = torch.device("cuda" if torch.cuda.is_available() else "cpu")
网络训练
train.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48import torch
import torch.nn as nn
from torch import optim
from models import Model
from datasets import data_loader, text_ClS
from configs import Config
import os
model_path = "models"
if not os.path.exists(model_path): #mkdir函数用于创建单级目录,makedirs函数用于创建多级目录
os.mkdir(model_path)
cfg = Config()
#加载数据
data_path = "sources/weibo_senti_100k.csv"
data_stop_path = "sources/hit_stopwords.txt"
dict_path = "sources/dict.txt"
dataset = text_ClS(dict_path, data_path, data_stop_path)
train_dataloader = data_loader(dataset, cfg)
#加载模型
cfg.pad_size = dataset.max_len_seq
model_text_cls = Model(cfg)
model_text_cls.to(cfg.devices)
#损失函数
loss_func = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(model_text_cls.parameters(), lr = cfg.learn_rate)
for epoch in range(cfg.num_epochs):
for i, batch in enumerate(train_dataloader):
label, data = batch
data = torch.as_tensor(data).to(cfg.devices)
label = torch.as_tensor(label, dtype = torch.int64).to(cfg.devices)
pred = model_text_cls.forward(data)
loss_val = loss_func(pred, label)
print("epoch is {}, step is {}, val is {}".format(epoch, i, loss_val))
optimizer.zero_grad()
loss_val.backward()
optimizer.step()
if epoch % 10 == 0: #每十个epoch存一次模型
torch.save(model_text_cls.state_dict(), "model/{}.path".format(epoch))
