本节主要介绍了词嵌入的常用方法:Word2Vec。
Word2Vec
- 利用中心词来预测上下文词
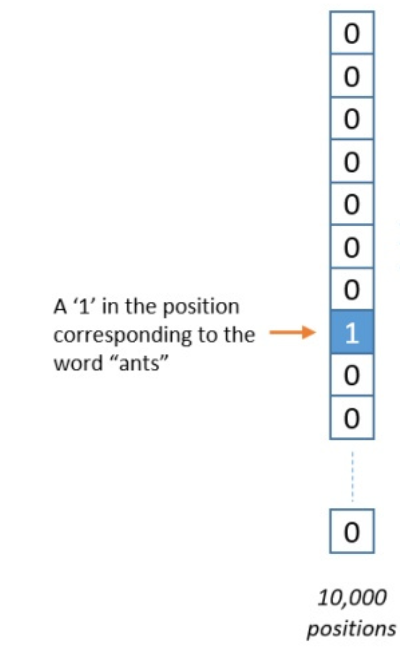
1.One-hot码
假设字典中1000个单词,则任意一个单词的表示为[0 0 …… 1 0 0……],即只在对应的单词为1,其他位置为0
例如:
2.嵌入矩阵
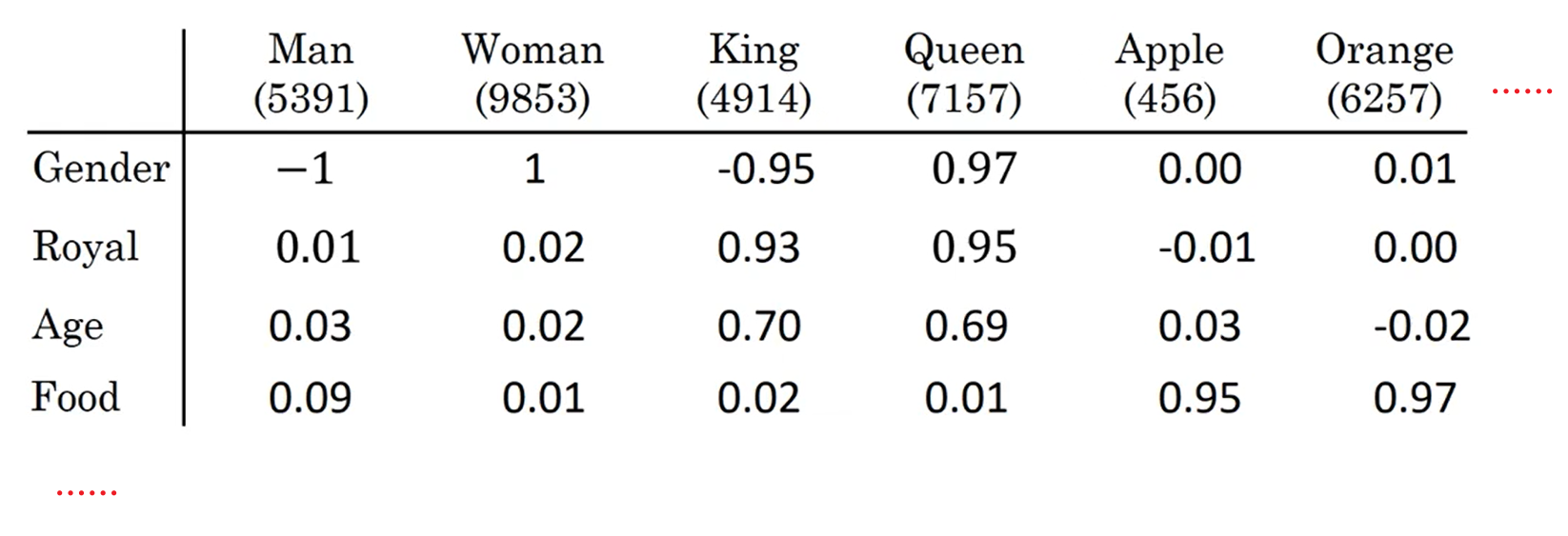
- 若每个词对应300个特征,那么嵌入矩阵为$300\times1000$
- 表中的权重代表词与对应特征的相关程度
3.Skip-gram模型
shkip-gram模型是基于某个词来生成它在文本序列周围的词
而模型训练时“周围的词”取决于skip窗口的大小
若文本序列为:you are the pretty sunshine of my life.
若skip窗口为2,那么中心词pretty、sunshine等的目标可能有如下:
| context | Target |
| ———— | ———— |
| pretty | are |
| pretty | the |
| pretty | sunshine |
| pretty | of |
| sunshine | the |
| sunshine | pretty |
| sunshine | of |
| sunshine | my |
| …… | …… |
模型结构:
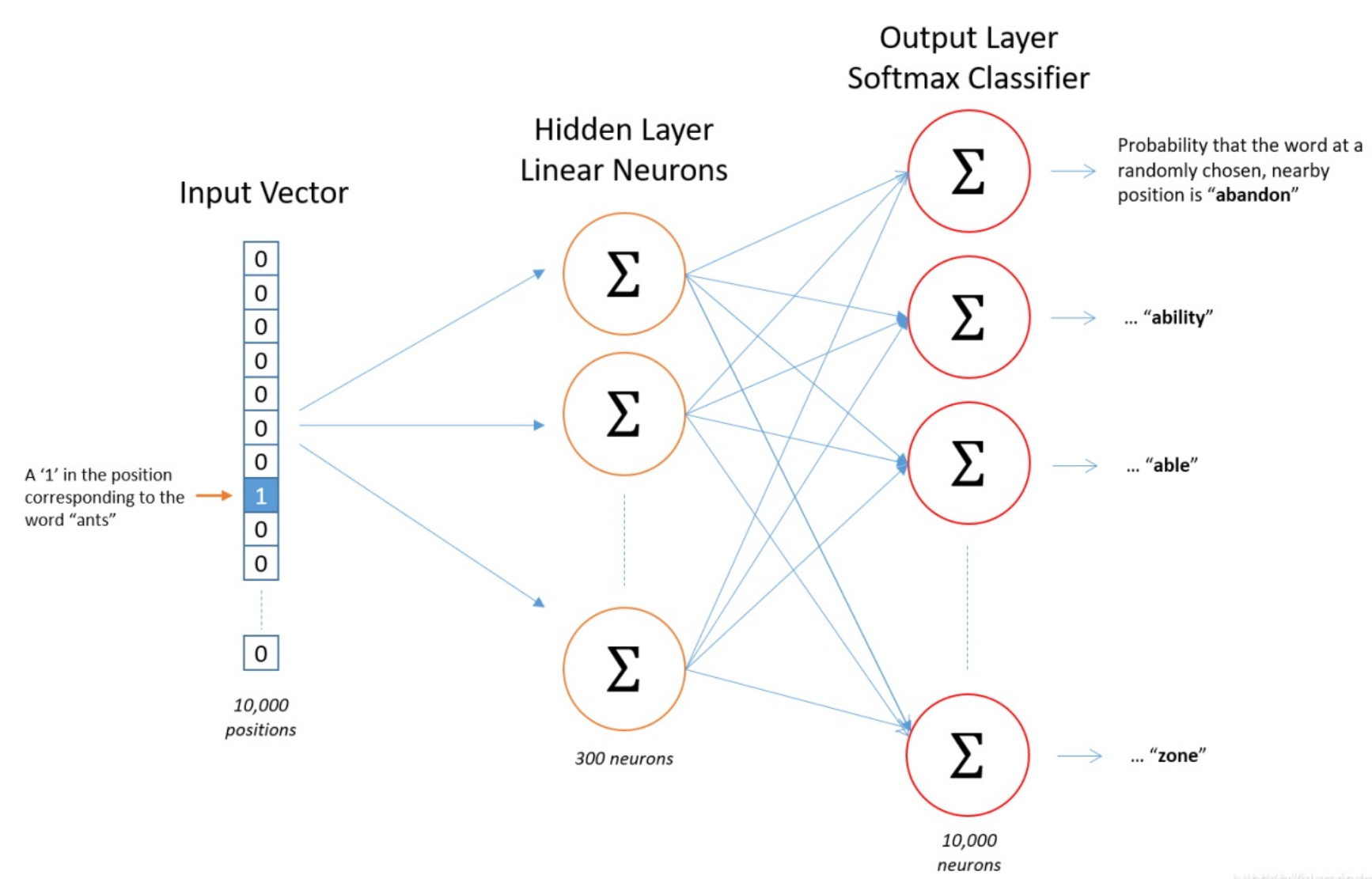
- 将上表中每个context看成训练样本的输入x,每个target看成训练样本的输出y
- Skip-gram可以表示为由输入层、隐藏层(不含激活函数)和输出层(激活函数为softmax)组成的神经网络
- 假设嵌入矩阵对应有300个特征,那么从输入层到隐藏层需要的权重矩阵(即为嵌入向量的转置)为$1000\times300$,从隐藏层到输出层需要的权重矩阵为$300\times1000$
4.负采样
针对计算softmax中分母计算量过大提出的一种解决方案
负采样的定义:在字典中随机选择一个词,标为0,即负样本
若文本序列为:I want a glass of orange juice to go alone with my cereal
则生成的正负样本有如下可能:正样本的生成方式与介绍skip窗口时相同
| context | word | target |
| ———- | ——- | ——— |
| orange | juice | 1 |
| orange | king | 0 |
| orange | book | 0 |
| orange | the | 0 |
| orange | of | 0 |
| …… | …… | …… |- 其中juice是给定的文本序列中抽取的,则orange-juice对为正样本,记为1
- king、book、the、of等都是随机中字典中抽取的词,则为负样本,记为0
- 数据集越大,从字典中挑取的样本个数就越小,反之亦然
模型结构:
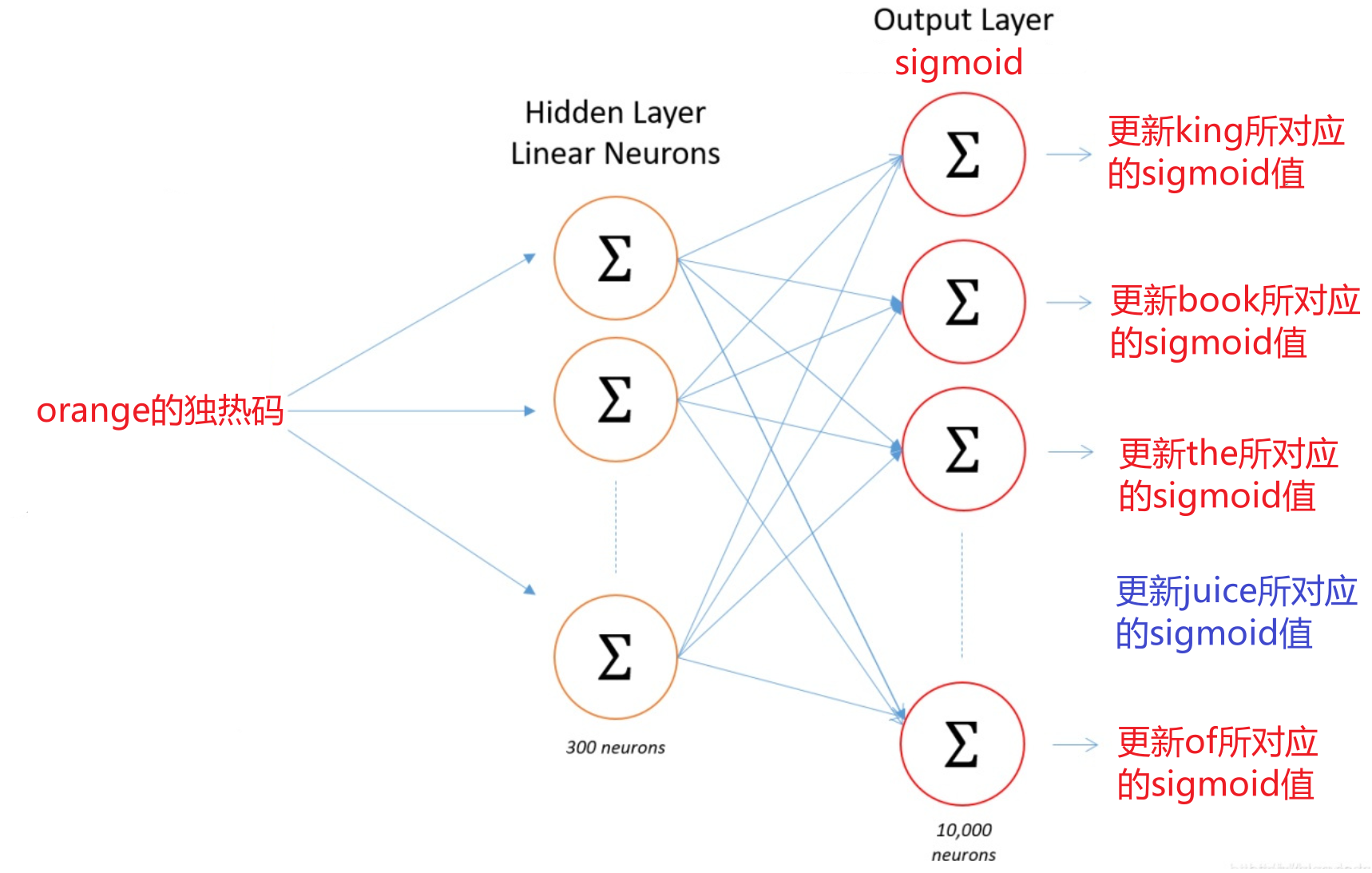
- 将每个单词所有可能的context与word共同看成训练样本的输入x
- 每个target看成训练样本的输出y
