本节主要介绍了卷积神经网络的基本结构,并通过Sequential模型对卷积神经网络进行了搭建。
深度学习基础
- 深度神经网络:有多层隐含层的神经网络
- 端到端学习:自动的从数据中学习特征
- 具有多层隐含层的深度神经网络就是深度学习(Deep Learning)
- 深度学习能够自动从数据中学习到与任务相关的特征,提取出的特征缺乏可解释性
图像卷积
1.图像卷积运算
- 首先,把卷积核和图像中的像素点一一对应
- 加权求和,把得到的结果作为中心像素点新的灰度值
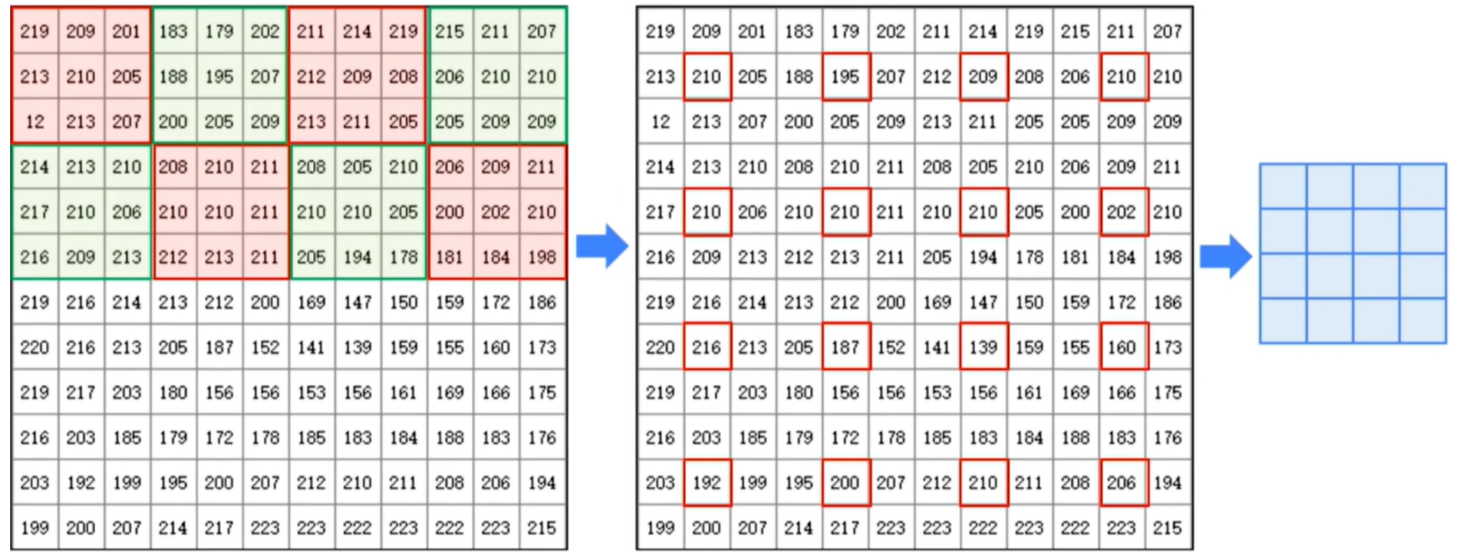
- 用卷积核从左至右,从上至下滑动,就可以计算出每个像素点的取值
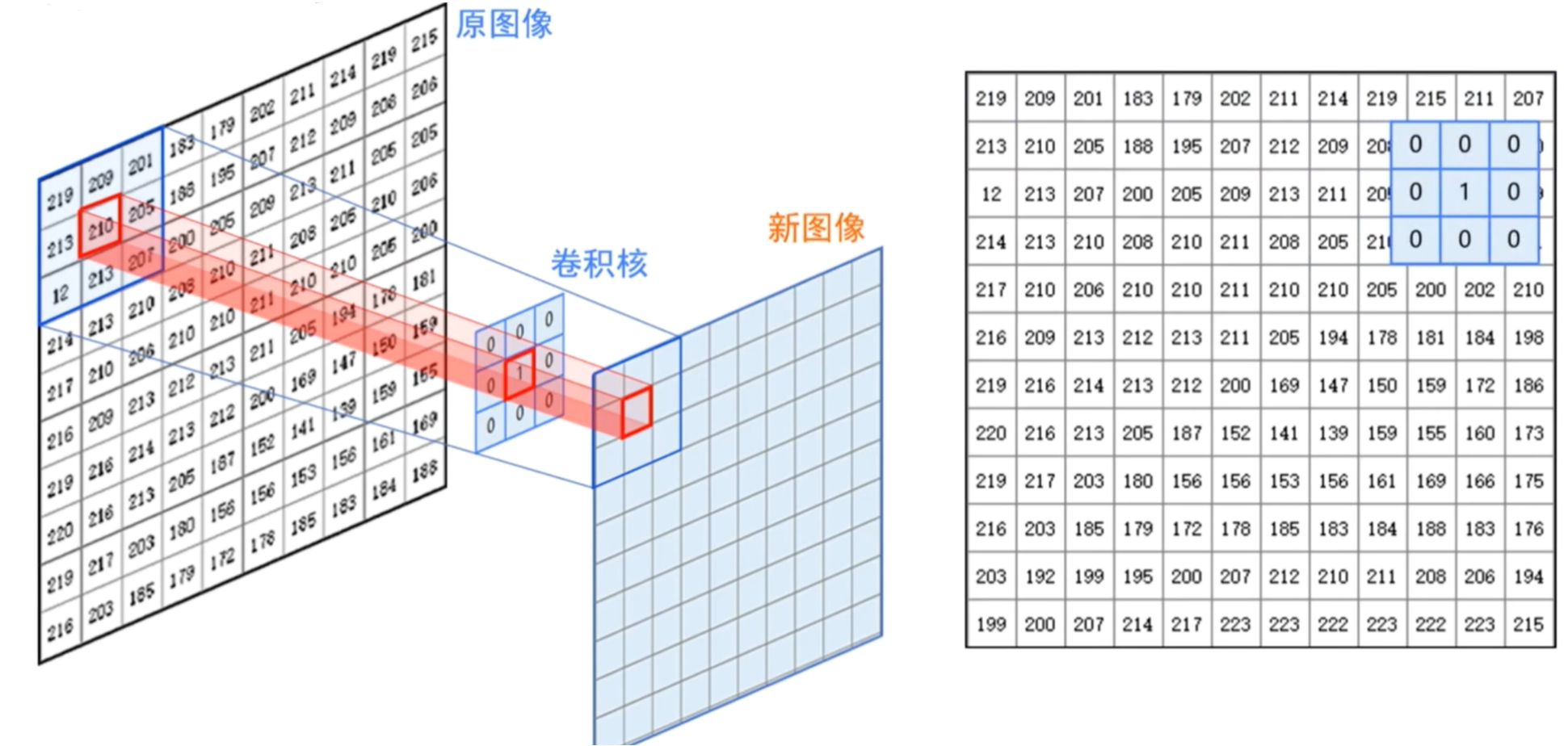
- 使用卷积核计算后的结果会比原图稍微小一点,因为对于图像边界上的点,无法进行卷积运算
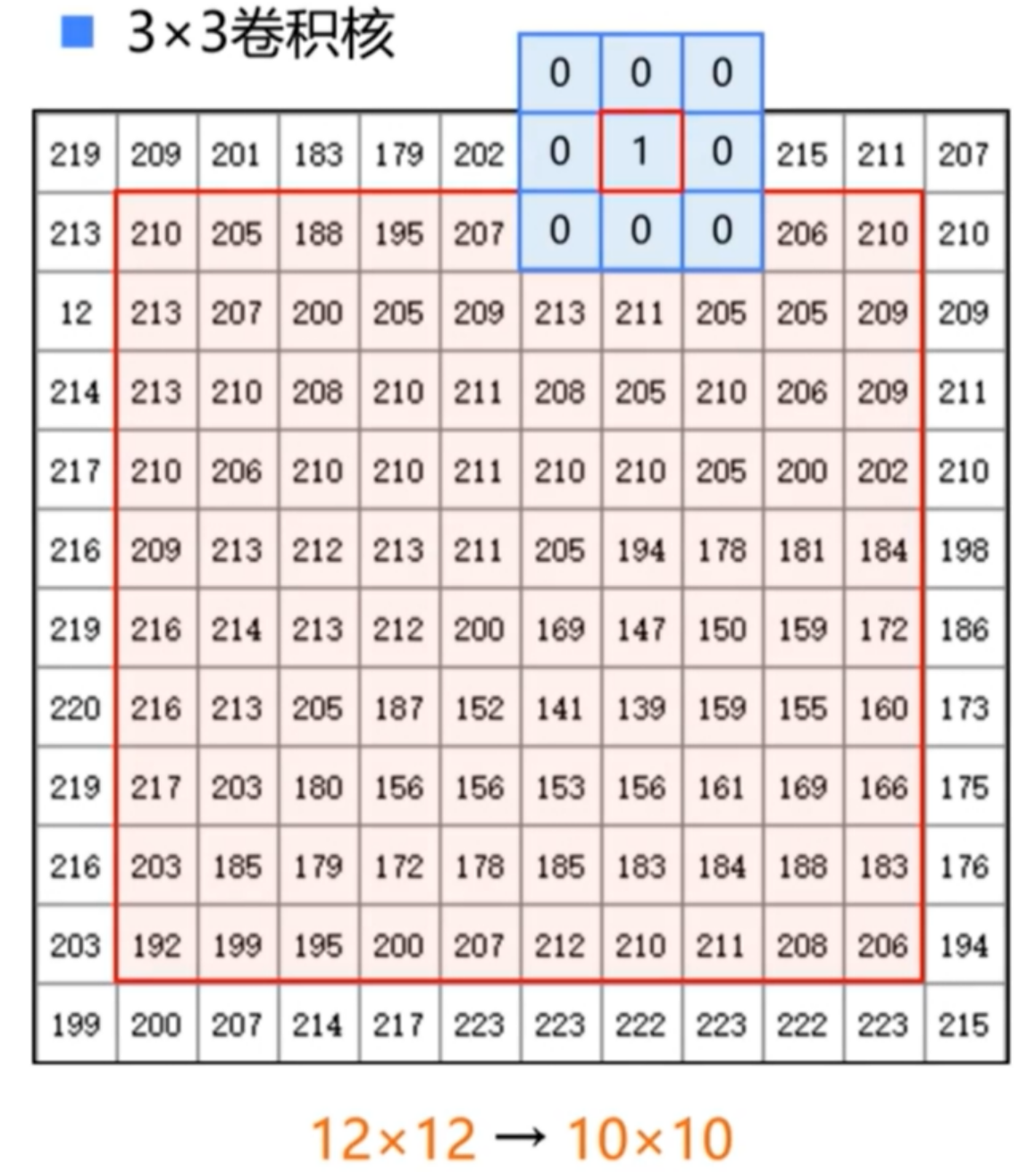
- 可以通过填充外层使得卷积后图像大小和原图一样
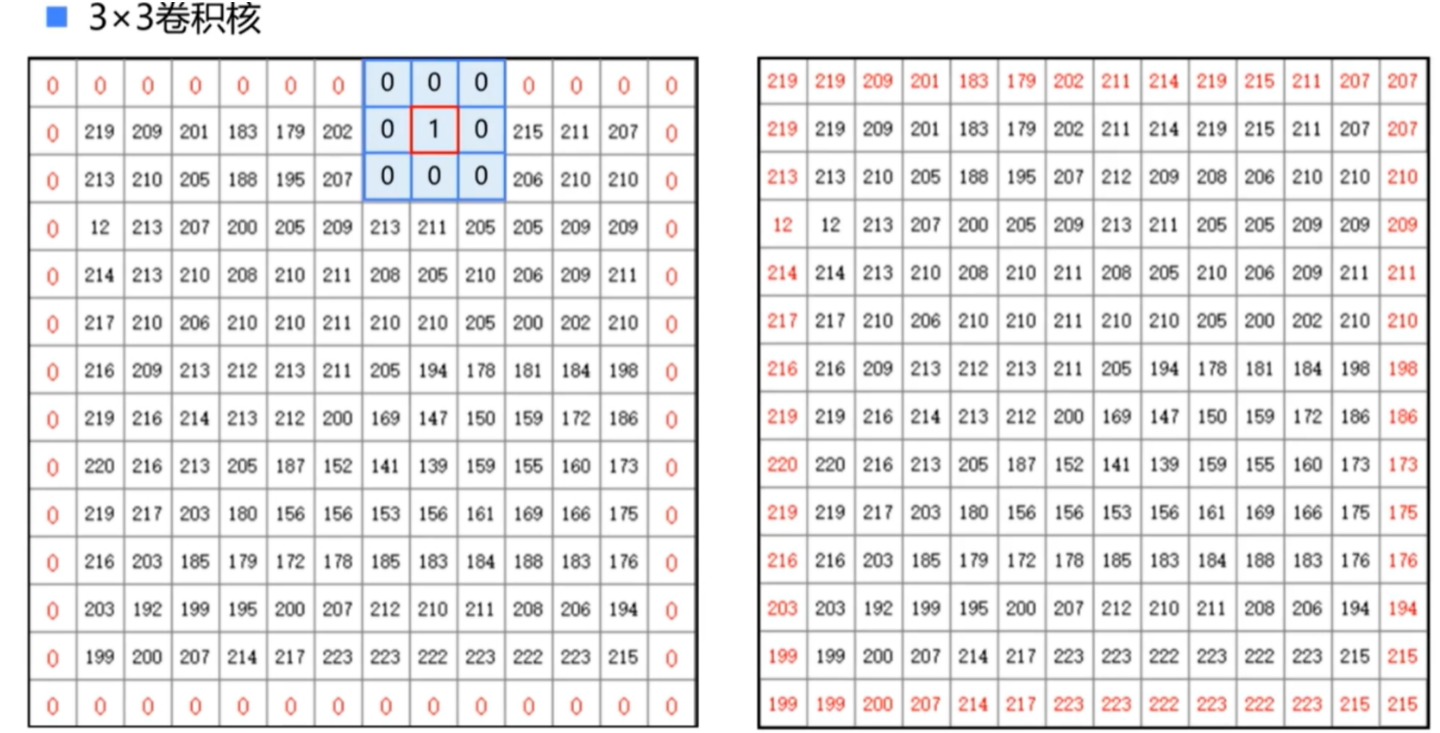
- 步长(stride):卷积核一次移动的像素数
- 步长等于卷积核的边长,相当于将图像缩小了n倍
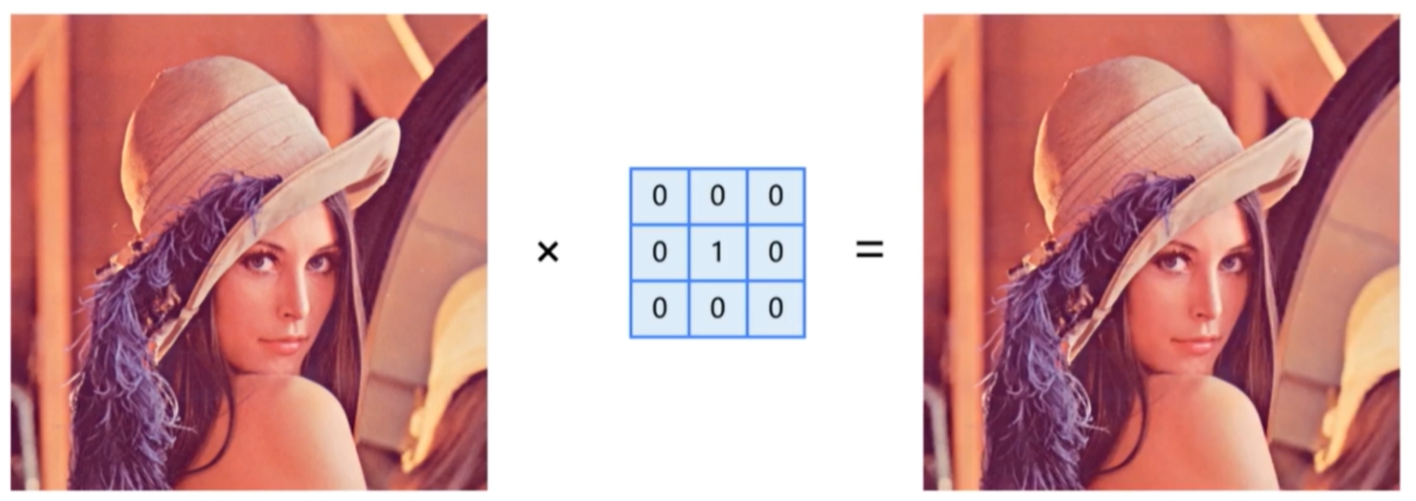
2.卷积核的作用效果
卷积核的尺寸,决定了周围像素的范围,卷积核的数值,表明了其权值,采用不同的卷积核,能够产生不同的效果
输出原图:
均值模糊:可以将图像中的高频噪声过滤掉,故对图像的卷积运算,也称为平滑或者滤波,卷积核也称为滤波器
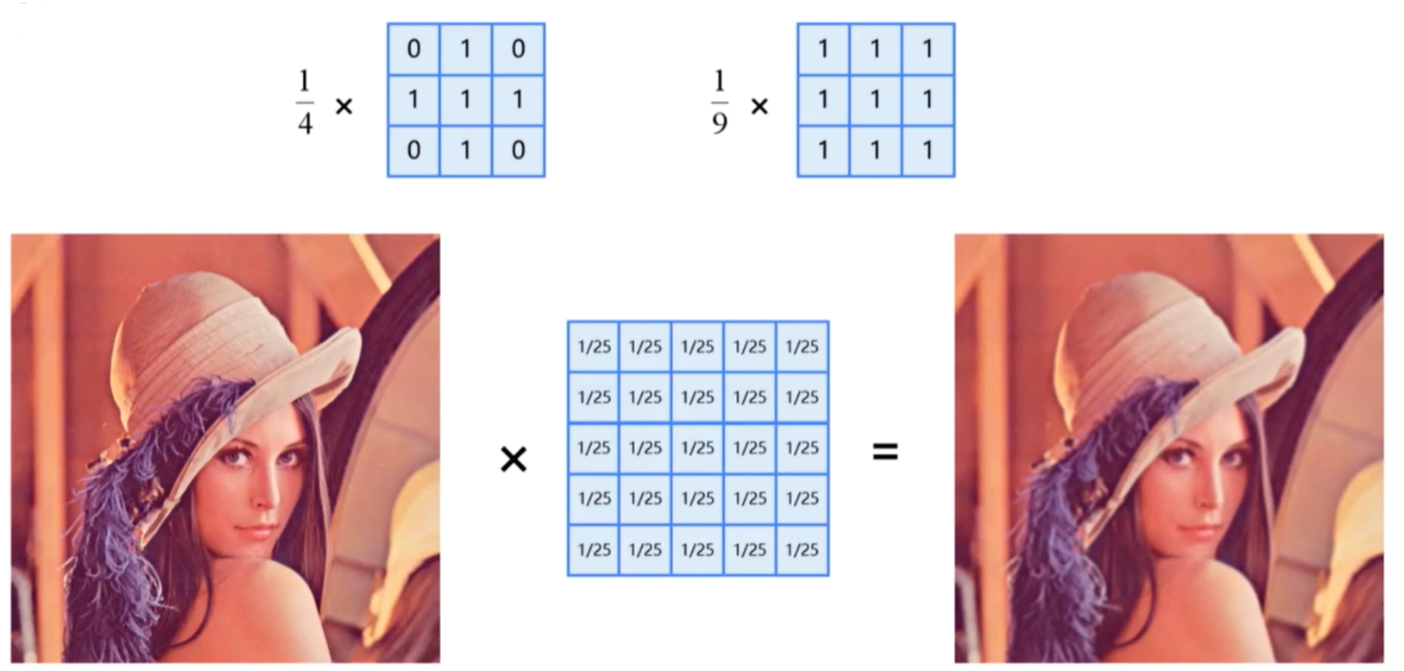
- 卷积核尺寸越大,图像越模糊

高斯模糊:根据高斯分布的取值来确定权值
- 为了尽可能保留图像中的边缘信息,给不同位置的像素点赋予不同的权值,离中心点越近的像素,权值越大,远离中心点的像素,权值也逐渐减小
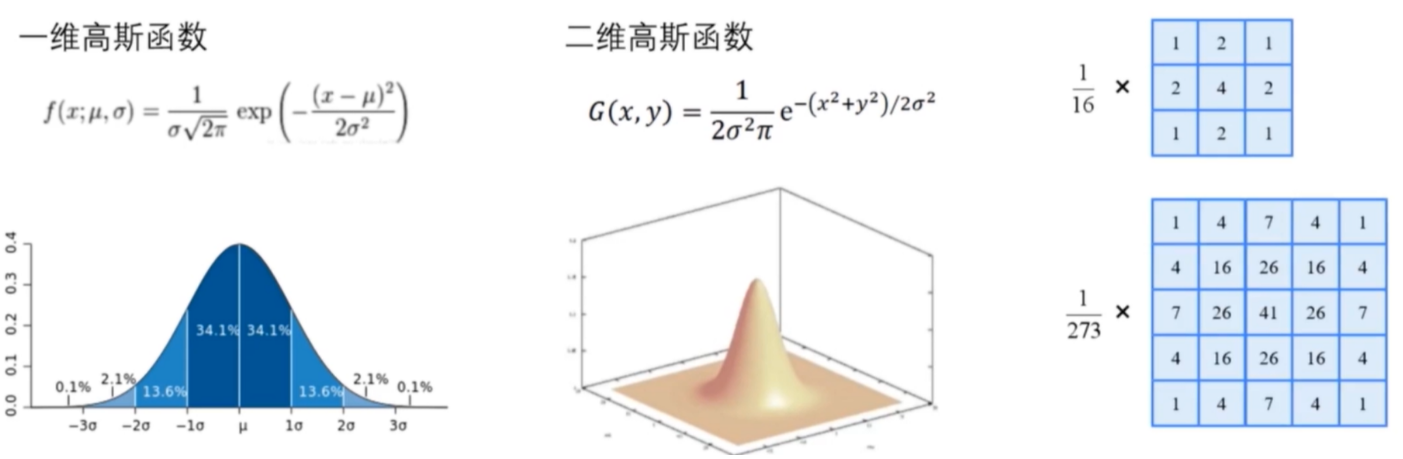
- 为了尽可能保留图像中的边缘信息,给不同位置的像素点赋予不同的权值,离中心点越近的像素,权值越大,远离中心点的像素,权值也逐渐减小
均值模糊与高斯模糊的对比:高斯模糊能够更好的保留图像的边缘和轮廓

3.边缘检测
- 计算当前点和周围点颜色值或灰度值的差别
- Prewitt算子:
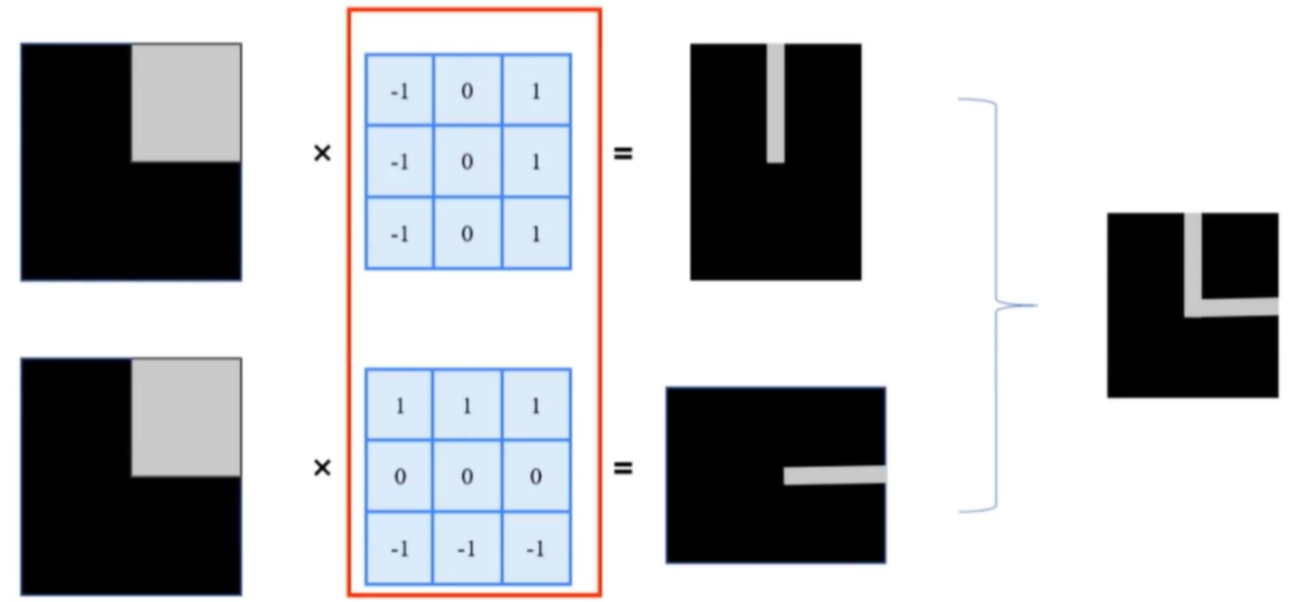
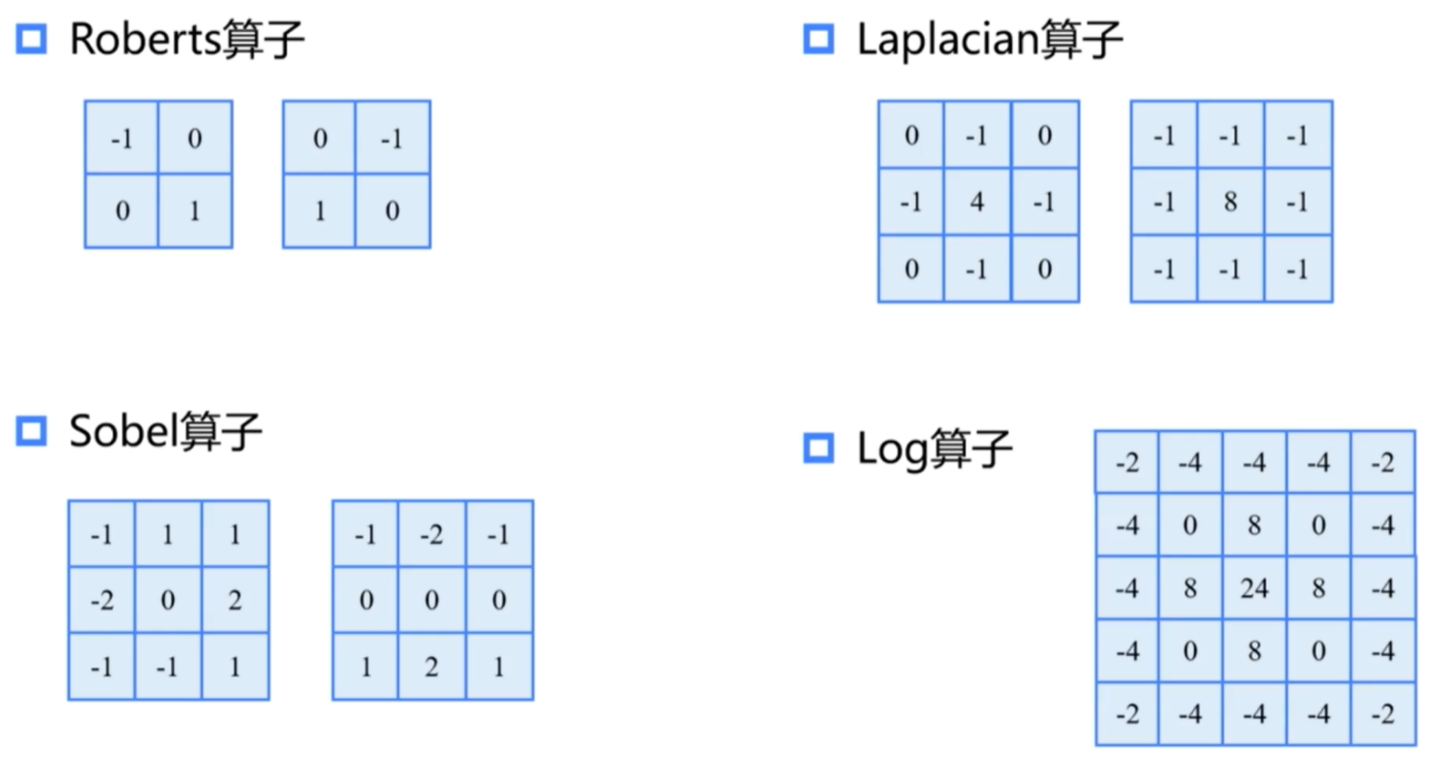
- Roberts算子:能够比较好的检测45°角方向的边缘
- Sobel算子:在Prewitt算子的基础上增加的权重的概念,认为上下左右直线方向的距离大于斜线方向的距离
- Laplacian算子:判断中心像素的灰度与邻域内其他像素灰度的关系
- Log算子:综合考虑了噪声的抑制和边缘检测,其抗干扰能力强,边界定位精度高,边缘连续性好,而且能有效提取对比度弱的边界
卷积神经网络
1.基本概念
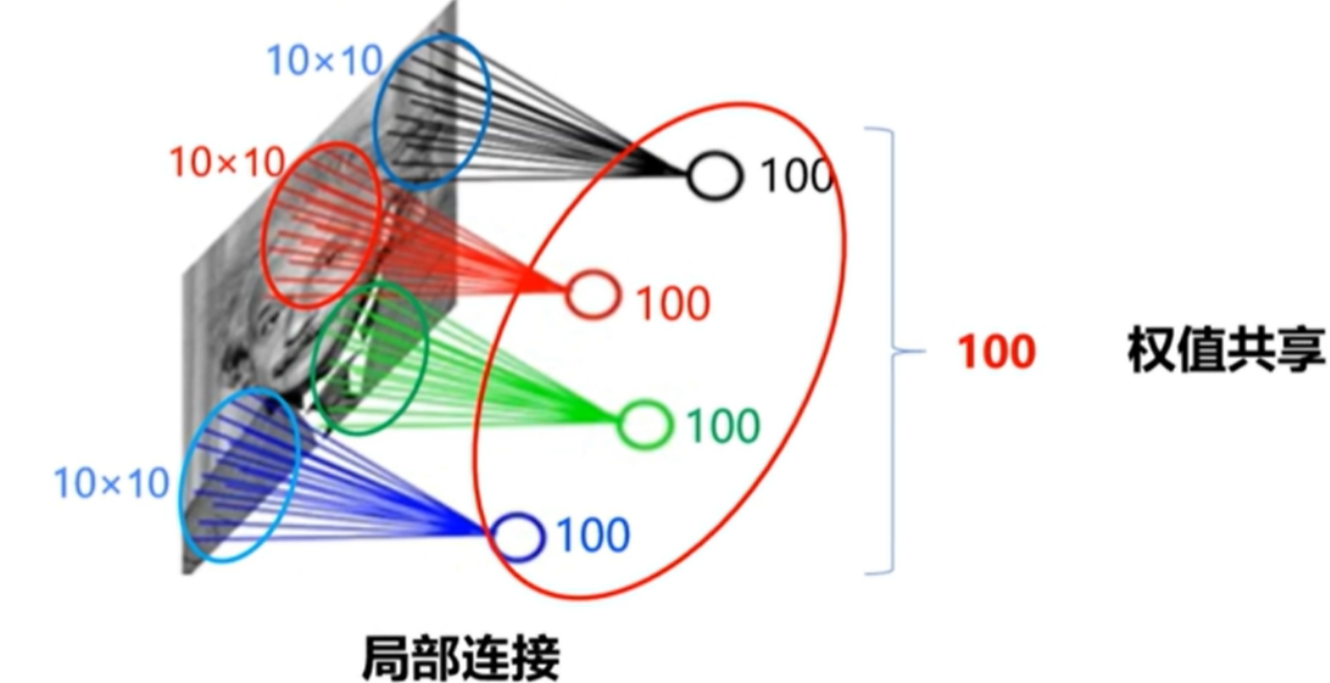
- 卷积神经网络中的每一个神经元相当于使用同一个卷积核(卷积核中的数值就是权重)在整个图像上滑动
- 一个卷积核只能提取一种特征,使用不同的卷积核提取不同的特征
- 卷积神经网络具有局部连接和权值共享的特点
- 卷积核中的权值是从数据中学习得到的
2.卷积神经网络的构成
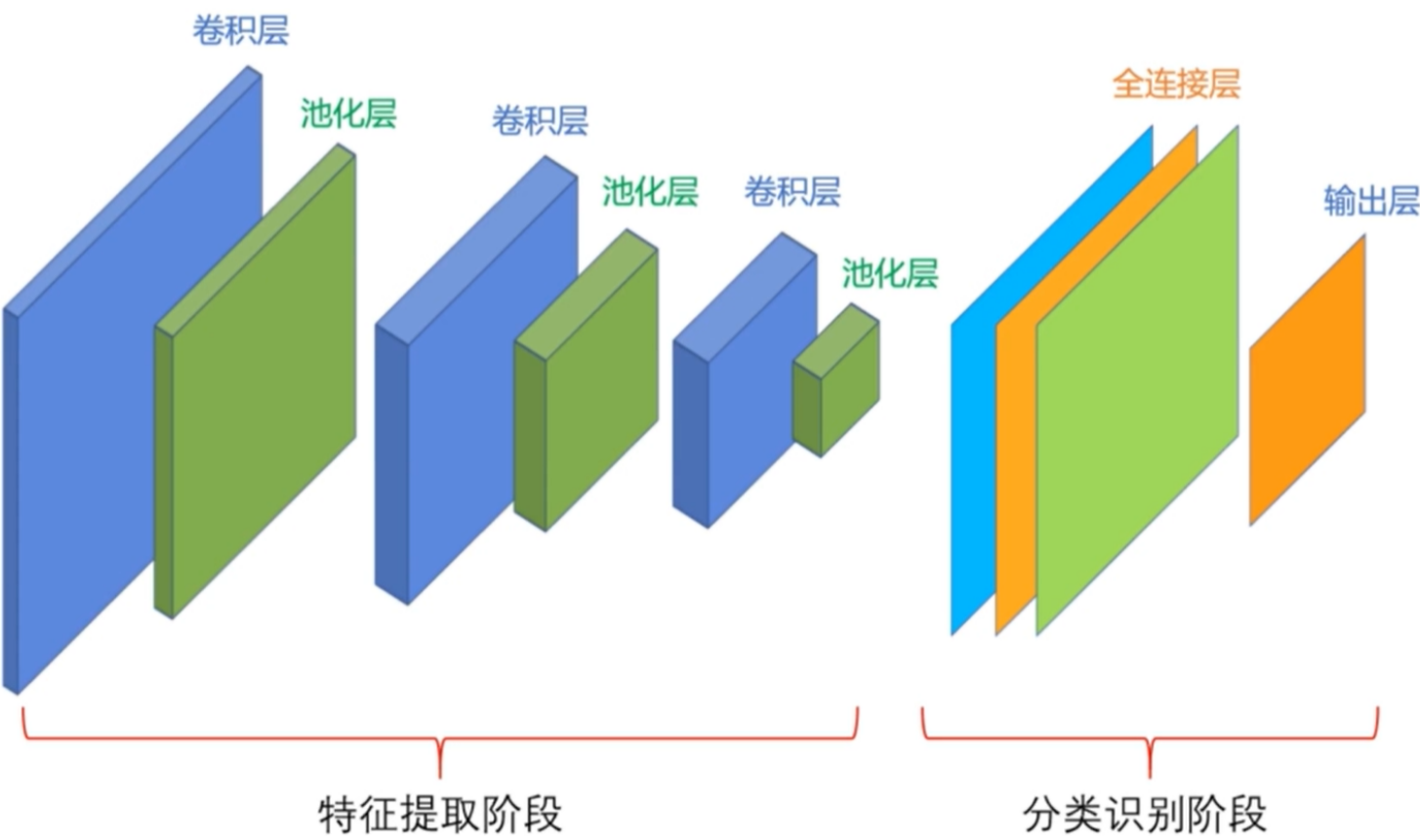
- 特征提取阶段
- 卷积层:特征提取层
- 每个卷积层中包含多个卷积核提取不同的特征
- 每个卷积核(每个卷积核又可能包含多通道)都输出一张特征图
- 激励函数:如ReLU
- 池化层:特征映射层
- 下采样:使用n×n的池化模板,且步长为n,将其尺寸减小到1/n
- 在减小数据的处理量的同时,保留有用的信息

- 卷积层:特征提取层
- 分类识别阶段:由全连接层或支持向量机组成
实例:卷积神经网络实现手写数字识别
1.创建卷积层
tf.keras.layers.Conv2D(filters,kernel_size,padding,activation,input_shape)- filters表示卷积核的数量
- kernel_size表示卷积核大小
- padding表示扩充图像的方式
- padding=”same”:以0扩充
- padding=”valid”:不扩充图像边界
- activation用来设置激活函数
- input_shape表示输入卷积层的数据形状,分别是samples(由batch_size自动指定),rows,cols,channels
1 | tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),padding="same",activation=tf.nn.relu,input_shape=(28,28,1))#因为MNIST数据集是灰度图像,所以通道数为1 |
2.创建池化层
tf.keras.layers.MaxPool2D(pool_size)- pool_size指定池化窗口的大小
1 | tf.keras.layers.MaxPool2D(pool_size=(2,2)) |
3.模型设计
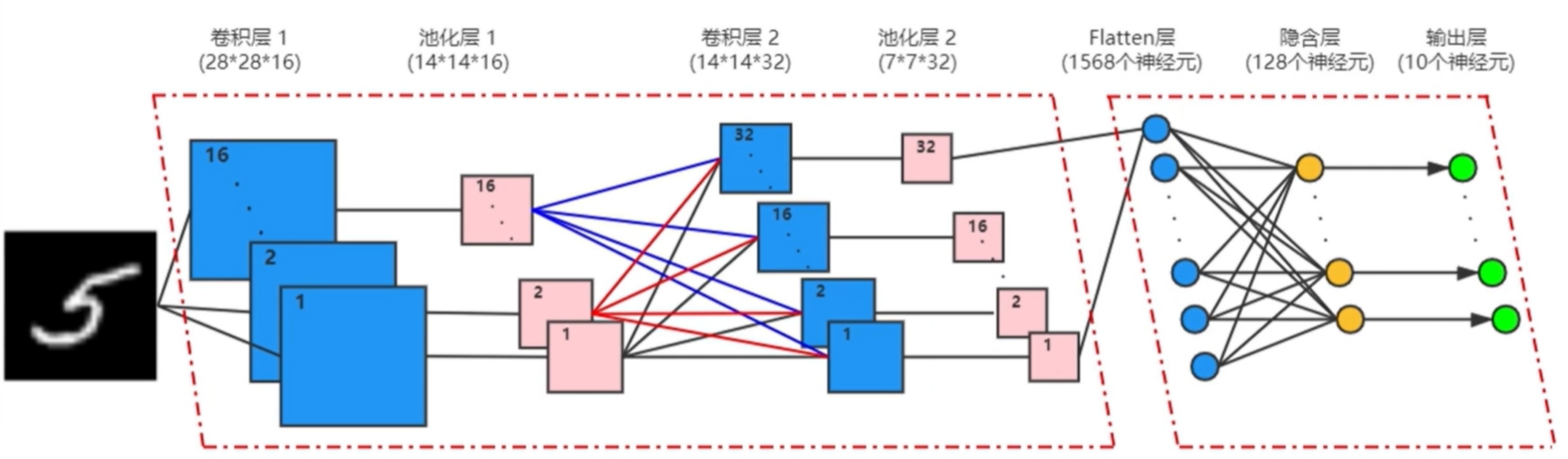
4.具体代码实现
1 | #1.导入库 |
结果如下:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 14, 14, 32) 4640
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 1568) 0
_________________________________________________________________
dense_4 (Dense) (None, 128) 200832
_________________________________________________________________
dense_5 (Dense) (None, 10) 1290
=================================================================
Total params: 206,922
Trainable params: 206,922
Non-trainable params: 0
_________________________________________________________________
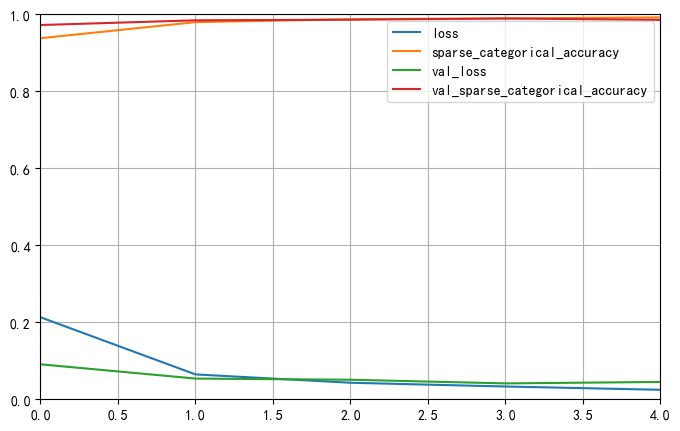
Epoch 1/5
750/750 [==============================] - 25s 32ms/step - loss: 0.2131 - sparse_categorical_accuracy: 0.9379 - val_loss: 0.0909 - val_sparse_categorical_accuracy: 0.9721
Epoch 2/5
750/750 [==============================] - 25s 33ms/step - loss: 0.0646 - sparse_categorical_accuracy: 0.9796 - val_loss: 0.0538 - val_sparse_categorical_accuracy: 0.9843
Epoch 3/5
750/750 [==============================] - 25s 34ms/step - loss: 0.0429 - sparse_categorical_accuracy: 0.9872 - val_loss: 0.0508 - val_sparse_categorical_accuracy: 0.9859
Epoch 4/5
750/750 [==============================] - 25s 34ms/step - loss: 0.0332 - sparse_categorical_accuracy: 0.9892 - val_loss: 0.0412 - val_sparse_categorical_accuracy: 0.9892
Epoch 5/5
750/750 [==============================] - 25s 33ms/step - loss: 0.0246 - sparse_categorical_accuracy: 0.9920 - val_loss: 0.0450 - val_sparse_categorical_accuracy: 0.9855
313/313 - 2s - loss: 0.0345 - sparse_categorical_accuracy: 0.9884

1 | #保存训练的模型参数 |
卷积神经网络的优化
1.Dropout():减少过拟合
- 随机让神经网络的某些隐含层节点停止工作,也就是让他们的权值为0
- tf.layers.Dropout(inputs,rate,seed=None,training=False,name=None)
- inputs为输入的张量
- rate指定神经元每一次随机被丢弃的比例
- seed丢弃固定位置的神经元
- trainning=True处于训练阶段时,才会进行dropout操作
- name表示dropout层的名称
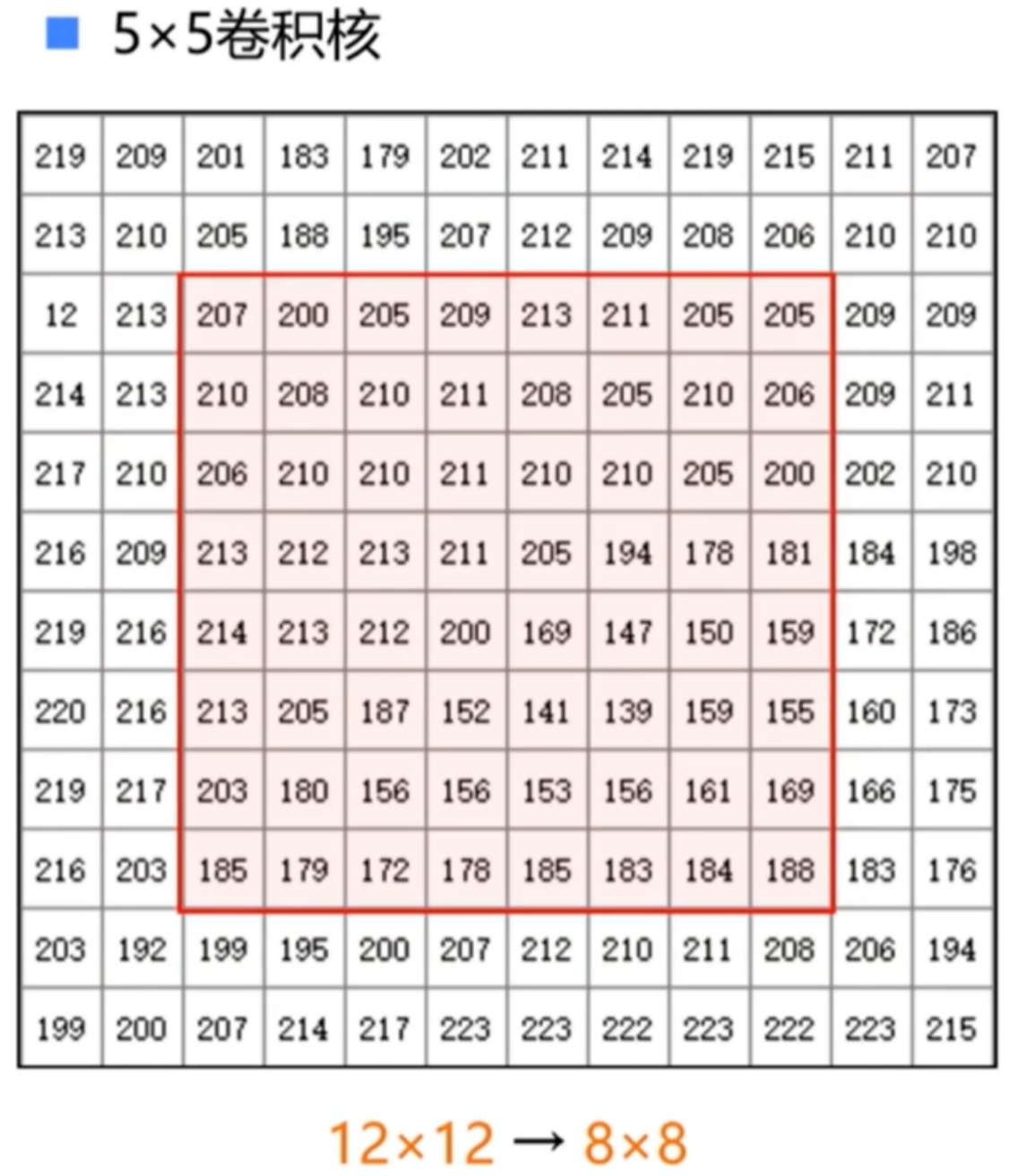
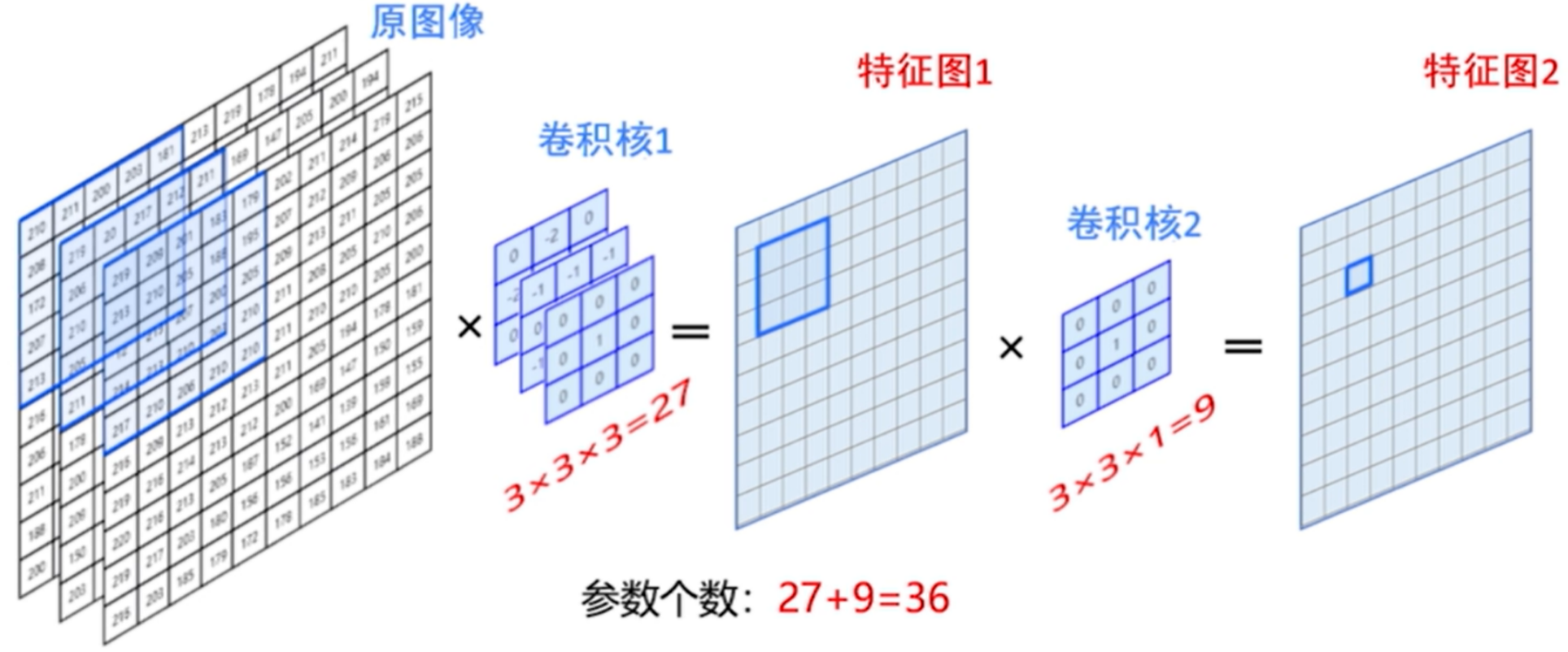
2.级联卷积核
- 使用两个3×3的卷积核级联与使用一个5×5的卷积核得到的感受野是一样的,但参数个数却少了
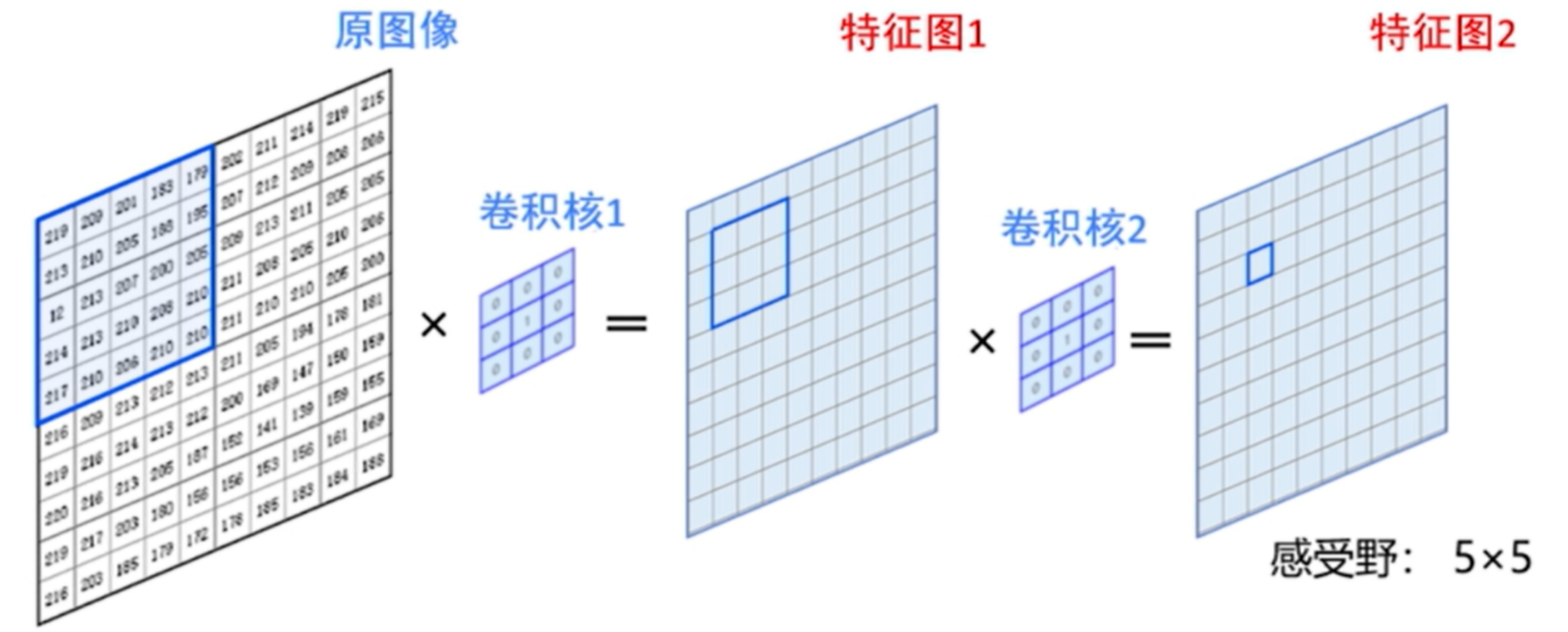
- 多通道的级联卷积核
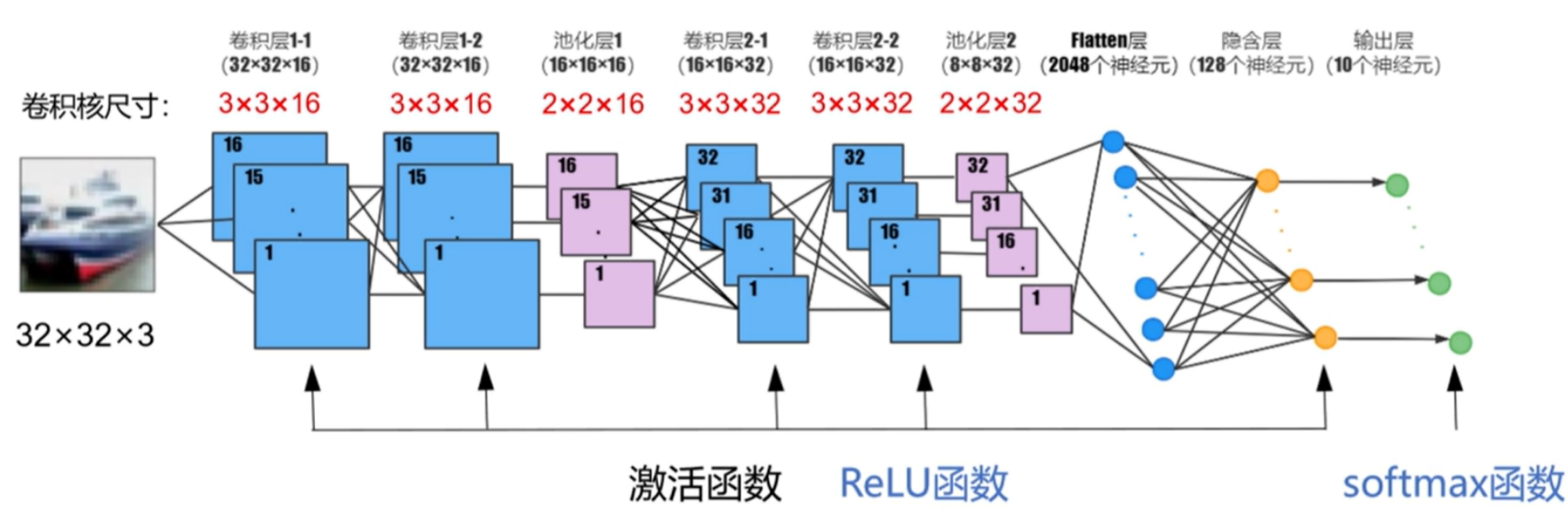
实例:卷积神经网络识别cifar10图片
1.设计卷积神经网络的结构
2.代码实现
1 | #1.导入库 |
结果如下:
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 32, 32, 16) 448
_________________________________________________________________
conv2d_7 (Conv2D) (None, 32, 32, 16) 2320
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 16, 16, 16) 0
_________________________________________________________________
dropout (Dropout) (None, 16, 16, 16) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 32) 4640
_________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 32) 9248
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 8, 8, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 8, 8, 32) 0
_________________________________________________________________
flatten_3 (Flatten) (None, 2048) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_6 (Dense) (None, 128) 262272
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_7 (Dense) (None, 10) 1290
=================================================================
Total params: 280,218
Trainable params: 280,218
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
625/625 [==============================] - 76s 120ms/step - loss: 1.6868 - sparse_categorical_accuracy: 0.3793 - val_loss: 1.3407 - val_sparse_categorical_accuracy: 0.5164
Epoch 2/10
625/625 [==============================] - 76s 122ms/step - loss: 1.3250 - sparse_categorical_accuracy: 0.5247 - val_loss: 1.1971 - val_sparse_categorical_accuracy: 0.5724
Epoch 3/10
625/625 [==============================] - 76s 122ms/step - loss: 1.1885 - sparse_categorical_accuracy: 0.5766 - val_loss: 1.0775 - val_sparse_categorical_accuracy: 0.6217
Epoch 4/10
625/625 [==============================] - 75s 121ms/step - loss: 1.1078 - sparse_categorical_accuracy: 0.6027 - val_loss: 1.0216 - val_sparse_categorical_accuracy: 0.6404
Epoch 5/10
625/625 [==============================] - 75s 121ms/step - loss: 1.0438 - sparse_categorical_accuracy: 0.6285 - val_loss: 0.9560 - val_sparse_categorical_accuracy: 0.6635
Epoch 6/10
625/625 [==============================] - 76s 122ms/step - loss: 0.9973 - sparse_categorical_accuracy: 0.6466 - val_loss: 0.9293 - val_sparse_categorical_accuracy: 0.6713
Epoch 7/10
625/625 [==============================] - 76s 121ms/step - loss: 0.9587 - sparse_categorical_accuracy: 0.6584 - val_loss: 0.9301 - val_sparse_categorical_accuracy: 0.6723
Epoch 8/10
625/625 [==============================] - 75s 121ms/step - loss: 0.9225 - sparse_categorical_accuracy: 0.6694 - val_loss: 0.8832 - val_sparse_categorical_accuracy: 0.6938
Epoch 9/10
625/625 [==============================] - 76s 121ms/step - loss: 0.8886 - sparse_categorical_accuracy: 0.6809 - val_loss: 0.8450 - val_sparse_categorical_accuracy: 0.6965
Epoch 10/10
625/625 [==============================] - 76s 121ms/step - loss: 0.8632 - sparse_categorical_accuracy: 0.6917 - val_loss: 0.8446 - val_sparse_categorical_accuracy: 0.7016
313/313 - 7s - loss: 0.8541 - sparse_categorical_accuracy: 0.7033
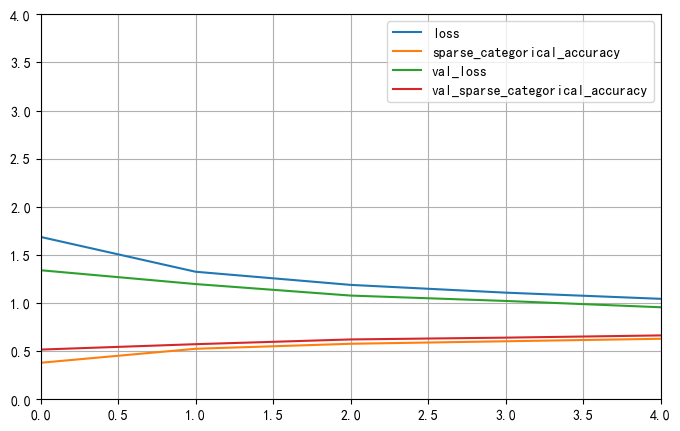

1 | #保存所有模型与数据 |
